

进入2020年代中期,高性能计算正逐步走出其“monolithic”时代。在过去大约五十年的时间里,性能的提升始终紧随光刻工艺的微缩步伐——即在单一、完整的硅基底上刻蚀出尺寸日益缩小的晶体管。尽管向埃级(angstrom-class)制程节点迈进的势头仍在延续,但推动系统级扩展的主要驱动力已悄然发生转变。如今,技术发展路线图的制定,已不再主要取决于晶体管本身的特性,而是日益侧重于工程师如何对功能模块进行解耦,并通过先进的互连技术将其重新整合。
物理学原理与经济学因素正共同推动着这场架构层面的变革。光刻扫描仪将最大曝光视场限制在 26 mm × 33 mm(约 858 mm²)的范围内;受这一掩模版尺寸上限的制约,单个单片式芯片(monolithic die)的实际尺寸也随之受到了有效限制。与此同时,在现代 AI 工作负载中,用于在存储层级体系内传输数据所耗费的时间与能耗正呈现出日益增长的趋势。动态随机存取存储器(DRAM)的访问操作所消耗的能量,往往比简单的算术运算高出数个数量级;因此,数据传输环节往往在功耗与性能表现上占据了主导地位。面对这一挑战,芯片设计人员正采取相应的应对策略:将处理器拆分为多个专司其职的独立芯片单元(分别负责计算、缓存、I/O 功能,且通常包含堆叠式存储器),并通过先进的封装技术与高带宽互连接口,将这些功能单元集成于同一芯片封装之中。
本文分析了促成这一转型的三项关键技术:玻璃基板、通用小芯片互连标准(UCIe)以及计算快速互连(CXL)。
1. 玻璃基板正日益成为一种重要的封装平台。通过用玻璃替代传统的有机树脂芯材,包括英特尔(Intel)和 SKC 旗下 Absolics 在内的多家企业正致力于减少封装翘曲现象,并支持更大尺寸(约 100 mm × 100 mm)的封装体,其互连密度远高于许多基于有机基板的方案。
2. UCIe 是一项标准化的裸片间(die-to-die)互连接口技术,旨在使来自不同工艺节点及不同供应商的小芯片(chiplets)能够在同一封装体内实现协同工作。
3. CXL 技术实现了跨组件的内存扩展与内存池化功能。借此,CXL 能够有效提升内存资源的利用率,并有助于解决人工智能(AI)集群中普遍存在的“孤立内存”(stranded memory)问题。
综合来看,上述各项技术共同推动了业界所谓的“超越摩尔定律”(More than Moore)4 这一发展趋势;在这一趋势下,性能的提升不再主要依赖于晶体管尺寸的微缩,而是更多地源于那些能够实现更高效数据传输的架构设计。
物理基础:玻璃基板
从有机基板向玻璃基板的过渡,标志着半导体封装领域的一次重大转变。英特尔(Intel)曾表示,计划在本十年后半段引入玻璃基板技术。在2026年的国际消费电子展(CES)上,英特尔发布了Xeon 6+处理器(代号“Clearwater Forest”),这是业界首款采用玻璃核心基板进行大规模量产(HVM)的产品。
然而,英特尔并非孤军奋战。SKC的子公司Absolics已在其位于佐治亚州的工厂启动了原型产品试产工作(这也是首批获得《芯片法案》资助的先进封装材料投资项目之一)。Absolics的目标是力争在2025年内实现量产准备就绪。与此同时,三星电子(Samsung Electronics)正探索将其先进封装技术与玻璃中介层相结合,并计划于2028年正式采用该技术;而三星电机(Samsung Electro-Mechanics)也正在积极研发玻璃基板。据规划,相关原型产品预计将于2025年第二季度问世。
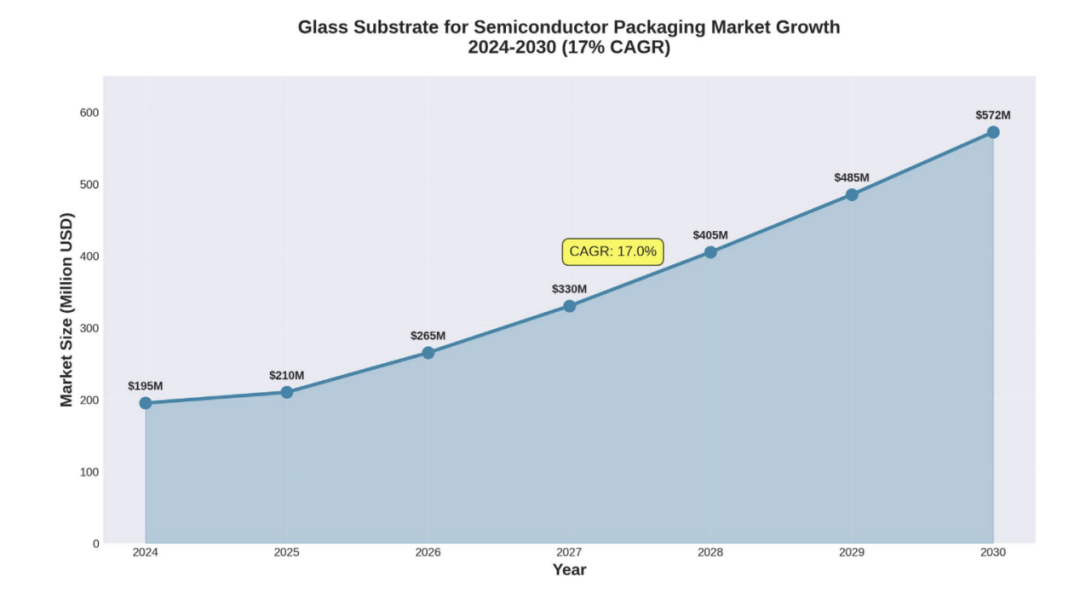
此外,AGC、康宁(Corning)和肖特(SCHOTT)等主要玻璃供应商,也正提供经过优化的基板级玻璃配方,旨在实现理想的热膨胀系数(CTE)匹配及低介电损耗特性。据行业分析师预测,在乐观的市场采纳情景下,玻璃核心基板市场规模有望在2030年达到4.6亿美元。
翘曲与有机材料的局限性
半导体行业之所以开始转向采用玻璃基板,部分原因在于有机基板正逐渐触及其机械性能的极限。在过去二十多年里,该行业一直依赖有机基板——这类基板通常以玻璃纤维增强环氧树脂为核心层,并逐层叠构上味之素堆积膜(ABF)。尽管对于消费电子产品及标准型中央处理器(CPU)而言,此类基板具有极高的成本效益;然而,随着封装体尺寸的不断增大及功耗的持续攀升(正如当今大型人工智能加速器所呈现的那样),翘曲现象及其他机械性能方面的制约因素正变得愈发难以有效管控。
一种值得关注的失效机制源于热膨胀系数(CTE)的不匹配。硅的热膨胀系数约为 2.6 至 3.0 ppm/°C。而有机基板(通常为聚合物基复合材料)的热膨胀系数则较高且变动性较大,通常在 12 ppm/°C 至 17 ppm/°C 左右。由于封装体与 PCB 所用材料的热膨胀系数各异,当温度升降时,二者的膨胀与收缩幅度不尽相同,从而在焊点处产生机械应力。因此,便会导致翘曲现象的发生。
当芯片尺寸较小时,由此产生的应力往往处于可控范围。然而,随着封装尺寸不断增大,以支持大型 AI ASIC 和高带宽存储器(HBM)堆栈,这种应力会在基板上逐渐累积,并引发翘曲;一旦规模扩大,这种翘曲将对良率产生实质性的影响。当基板发生弯曲时,用于连接硅裸片与基板的焊料凸点(即“受控塌陷芯片连接”/C4 凸点)可能会发生脱离并形成开路,或者发生桥接并引发短路。
相比刚度更高的替代材料,有机基板在尺寸稳定性方面往往稍逊一筹。在那些高功率数据中心处理器中——其功耗甚至可逼近 1000 瓦——散热硬件往往会施加巨大的夹紧力。由于有机基板的刚度(以杨氏模量衡量)通常低于玻璃或硅基基板,因此在受力负载下更容易发生弯曲变形,进而增加芯片开裂或互连结构受损的风险。截至 2024 年底,许多技术路线图及相关技术研讨已趋于达成共识:对于下一代系统级封装(System-on-Package)设计所设定的互连密度及机械性能要求而言,有机基板将难以满足其规模化扩展的需求。
玻璃芯基板的材料科学
玻璃基板通过其材料特性,有效应对了上述机械和热学方面的挑战。通过采用硼硅酸盐玻璃或熔融石英玻璃作为基板芯材,制造商能够对基板的热膨胀系数(CTE)进行精确调控,使其与硅芯片(die)实现更紧密的匹配。更优良的CTE匹配有助于减轻基板翘曲现象,从而为承载更大尺寸的封装体提供有力支撑——其中包括尺寸超过 100 mm × 100 mm 的大型封装体。这一点对于所谓的“突破掩模版限制”(reticle-busting)设计尤为关键;在这类设计中,多枚尺寸逼近极限的芯片会被拼接整合在一起。
一、尺寸稳定性和平坦度
对于光刻工艺而言,玻璃的刚性同样至关重要。玻璃具有相对较高的杨氏模量,其刚度更接近于陶瓷而非有机层压板,与此同时,它仍可被制造成薄型基板。这种高刚度特性有助于改善对总厚度变化(TTV)的控制。
在先进封装领域,光刻工艺的焦深通常较浅。如果基板表面存在波纹起伏,则精细特征可能无法在整个表面区域内实现均匀的分辨。更为平坦的玻璃表面有助于更稳定、一致地实现精细线条与间隙的图形化。
这种优异的尺寸稳定性使得玻璃基板能够支持比有机基板更高密度的基板级布线和垂直互连。有机基板往往难以进一步缩小凸点间距和过孔间距,因为其固有的翘曲问题及热膨胀系数(CTE)失配可能会导致良率下降¹⁹。以英特尔(Intel)为例,据其估算,若将玻璃通孔(TGV)的间距缩小至约 100 µm(相比之下,有机基板上机械钻孔的间距约为 325 µm),通孔密度将实现约一个数量级的提升。通常而言,小于 10 µm 的极小间距主要应用于芯片间的混合键合技术(例如英特尔的 Foveros Direct),而非封装基板本身。更高的互连密度意味着更高的 Chiplet(小芯片)带宽,以及更低的单位比特能耗。其他关于玻璃基板的演示案例也报告了在基板级特征微缩方面呈现出类似的趋势。
二、玻璃通孔(TGV)
玻璃基板的一项关键特性在于其玻璃通孔(TGV)结构。在有机基板中,垂直互连通常是通过对聚合物芯层进行机械钻孔或激光钻孔来实现的;然而,这种方式可能会限制通孔之间间距的紧密程度。相比之下,TGV 是利用诸如激光诱导深刻蚀(LIDE)等工艺在玻璃基板中形成的,这些工艺能够支持更精细的特征尺寸及更紧密的间距。
得益于这些工艺,人们能够制造出具有高深宽比的通孔——即贯穿玻璃基板、既极其狭窄又深度极深的“隧道”结构。英特尔(Intel)已成功展示了在厚度为1毫米的基板中实现的TGV,其深宽比高达20:1,通孔直径小至75微米。这种能够将通孔紧密排布(即实现精细间距)的能力,不仅缩短了信号传输所需的路径长度,同时也降低了电源传输网络的电阻与电感。
三、电气与光学优势
除了机械特性之外,玻璃作为一种介质材料,在处理高频信号方面也展现出更优越的性能。相较于许多有机材料,玻璃通常具有更低的损耗角正切值(Loss Tangent)——这意味着在信号传输过程中,转化为热能而耗散掉的信号能量更少。随着封装级数据传输速率的不断攀升,有机基板所带来的信号损耗问题日益凸显,有时甚至迫使设计人员不得不引入额外的均衡电路或类似中继器的电路,从而导致功耗增加。玻璃材料有助于在更长的封装内部传输距离上保持信号的完整性;这一点尤为重要,因为随着封装尺寸的不断扩大,内部互连线路所覆盖的区域也随之增加。
此外,人们目前正积极探索利用玻璃材料来实现与光子技术的更紧密集成。由于玻璃具有光学透明性及优异的尺寸稳定性,它能够支持在基板内部或表面集成波导等光学元件。这一特性可与“共封装光学”(CPO)的概念相辅相成:在CPO架构中,光学引擎被紧邻计算芯片放置,从而使电信号能够在靠近信号源的位置即刻转化为光信号,进而实现更长距离的信号传输。
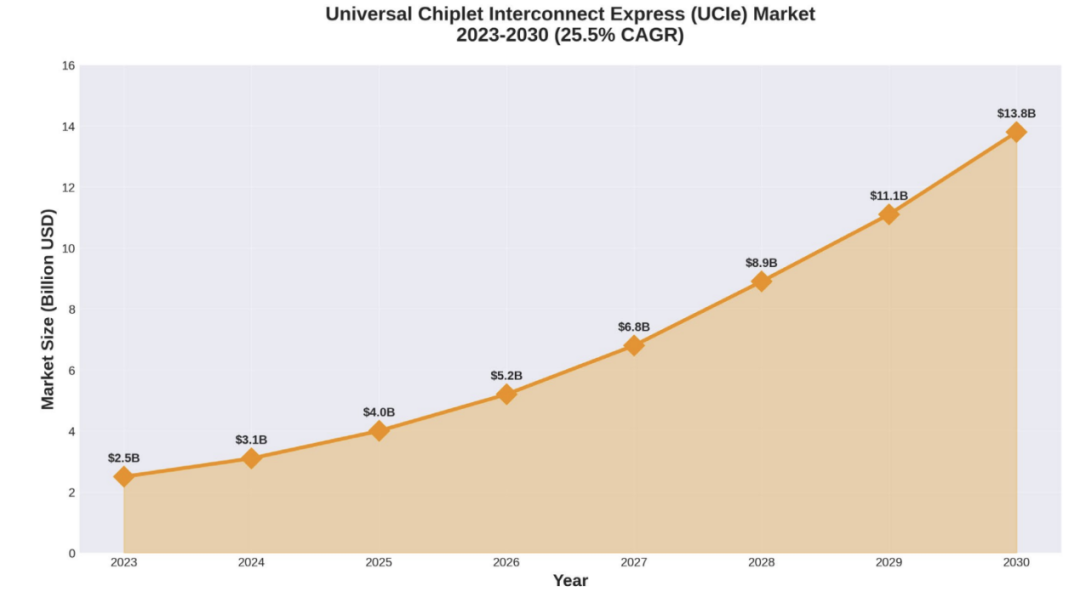
神经系统:UCIE( Universal Chiplet Interconnect Express )
如果说玻璃基板为当前的路线图提供了结构基础,那么通用小芯片互连 Express (UCIe) 则提供了一个连接层。对于“解构式硅片”(即大型单片裸片被拆分为更小的“小芯片”的架构)而言,若能利用一种标准化、高带宽且低延迟的接口将这些小芯片互连起来,将获益良多。若缺乏通用的标准,小芯片之间的互操作性将受到限制,且相关的生态系统也将主要局限于特定厂商的体系内。UCIe 正是提供了这种标准化、裸片对裸片(die-to-die)的接口,以满足基于小芯片的设计所需。解构式硅片——即大型单片裸片被拆分为更小的小芯片的架构——正是得益于这种高带宽、低延迟的接口,才得以将这些小芯片彼此连接。若无通用的标准,小芯片的互操作性将受限,且生态系统也将主要局限于特定厂商的体系内。UCIe 旨在提供一种通用的裸片对裸片接口,从而使小芯片能够跨越不同的工艺节点进行通信,在某些情况下,甚至能够实现跨厂商之间的通信。
标准的演进:从 1.0 到 3.0
UCIe 规范的演进历程,体现了业界对其迅速采纳的趋势。
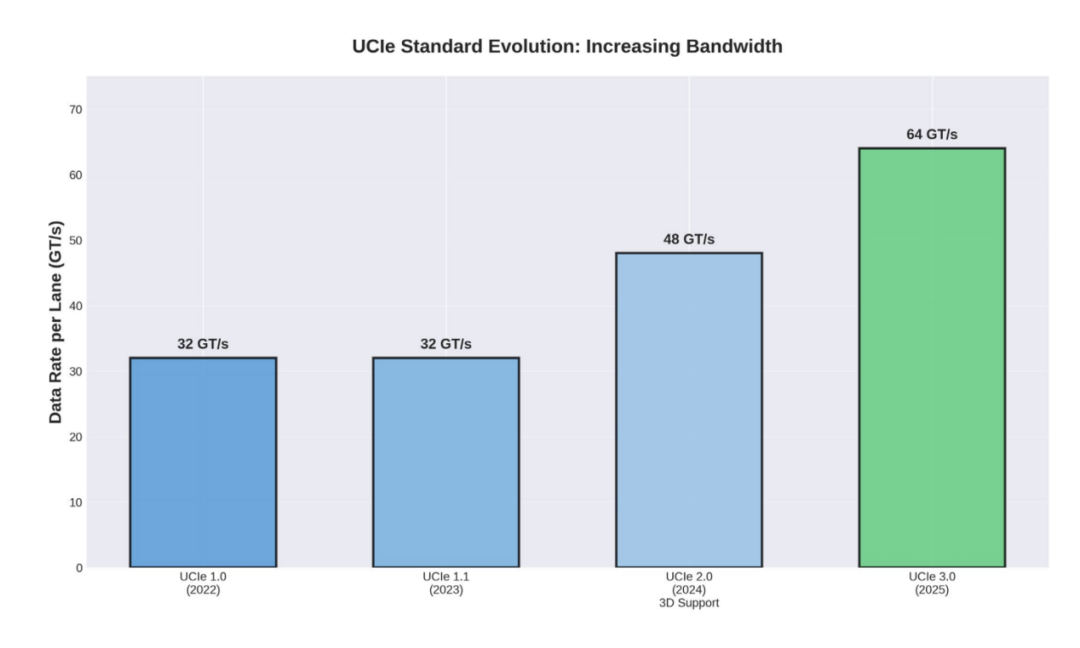
UCIe 1.0 和 1.1:这些初始版本主要致力于确立基准规范。它们定义了针对标准 2D 和 2.5D 封装的物理层(PHY)规范,并设定了带宽密度与能效(通常以“皮焦耳/比特”为单位表示)的目标指标。此外,这些版本还基于 PCIe 和 CXL 等广泛应用的协议构建,旨在确保协议栈上层的兼容性。
UCIe 3.0:于 2025 年 8 月发布的 UCIe 3.0 版本,支持高达 64 GT/s 的单通道数据速率,相较于早期版本,其带宽能力大致翻了一番。更高的链路带宽有助于满足现代 GPU 和加速器设计对数据传输日益增长的需求。
此外,UCIe 标准的适用范围也已扩展至涵盖 3D 集成领域。早期版本(1.0 和 1.1)主要聚焦于横向并列式(2D 和 2.5D)的连接方式。而 UCIe 2.0 版本则引入了对 3D 封装的支持,明确规定了旨在服务于 3D 裸片间(die-to-die)互连的电气与物理要求——其中包括允许小芯片(chiplets)直接垂直堆叠的“混合键合”(hybrid bonding)技术。相较于距离较长且呈横向分布的连接方式,垂直互连能够支持远高于前者的信号密度。从理论上讲,这一特性有助于像英特尔 Foveros Direct 3D 这样的技术方案,在与第三方小芯片及 IP 进行互操作时,实现更为顺畅、高效的协同工作。
UCIe 与模块化架构
UCIe 的价值在于,它能够使基于 Chiplet 的设计更具模块化特性。在单片式设计中,处理器的绝大部分组件都必须基于单一的工艺节点进行制造。如果一家公司希望在 3 纳米级节点上集成最尖端的 CPU 内核,往往不得不将 I/O 和模拟电路模块也一并置于该节点之上;尽管事实上,模拟电路并非总能很好地随工艺节点进行微缩,且在先进工艺节点下其制造成本往往会变得更为昂贵。
-
Compute tiles:采用台积电 N2 或英特尔 18A 等尖端工艺节点制造,旨在实现每瓦性能的最大化。
-
I/O tiles:采用台积电 N6 等更为成熟且兼具成本效益的工艺节点制造。此类tiles负责处理 PCIe 通道、USB、Thunderbolt 以及内存控制器功能。
-
Accelerator tiles:来自第三方供应商的专用 IP(例如 AI 推理单元或光 I/O 模块),通过 UCIe 互连技术进行连接。
这种解耦拆分有助于提升成本效益并改善良率。相较于超大型芯片,尺寸较小的芯片(Die)往往能实现更高的良率;此外,若将最尖端的制程节点优先留给那些能从中获益最大的功能模块,则可有效降低整体成本。UCIe 协议旨在使这些功能模块——即便它们采用不同的制程节点制造,甚至可能来自不同的供应商——也能以可预测的低延迟和极高的可靠性进行相互通信,从而使其表现更接近设计人员对片上互连(on-die links)所预期的理想水平。
分层架构与协议灵活性
UCIe 采用了一种受 OSI 模型启发的层次化架构,从而为多样化的应用场景提供了所需的灵活性。
1. 物理层(PHY):这是电气接口层。UCIe 定义了两种类型的物理层:标准封装(Standard Package,适用于采用标准凸点技术的有机基板)和高级封装(Advanced Package,适用于硅中介层、EMIB 等桥接技术以及 RDL 扇出技术)。高级封装物理层利用了这些基板所具备的精细布线能力,从而提供了显著更高的带宽密度(即“岸线效率”)。
2. 裸片间适配层(Die-to-die adapter):该层位于物理层之上,负责管理链路的可靠性。它处理循环冗余校验(CRC)以及重传机制。如果在传输过程中发生比特错误(尽管罕见,但确有可能发生),适配层将检测到该错误并自动重发数据,从而确保上层协议看到的始终是一条无误的链路。
3. 协议层:这是 UCIe 展现其多功能性的核心所在。该层支持将各类标准协议映射至 UCIe 链路上,例如 PCIe(用于连接外设)、CXL(用于实现缓存一致性内存扩展)以及流式协议(用于实现原始、低延迟的数据传输)。这意味着对于软件驱动程序而言,一条 UCIe 链路可以呈现为标准的 PCIe 插槽;而对于 CPU 硬件而言,它则可以呈现为一条具备缓存一致性的内存总线。
行业采纳情况
UCIe 日益获得行业认可的一个重要标志,便是其已被 NVIDIA 所采纳。从历史上看,NVIDIA 曾偏好使用其专有的 NVLink 互连技术来进行裸片间(die-to-die)及芯片间(chip-to-chip)的通信。然而,市场对定制化芯片(即 XPU)的需求激增,迫使 NVIDIA 实施了一项战略转型。
尽管 NVIDIA 仍继续使用 NVLink 来实现其 GPU 之间的互连(即机箱级扩展),但它已转而采用 UCIe 来集成客户定制的 IP 模块。例如,像 Google 或 Meta 这样的超大规模云服务提供商,可能会设计一款定制化的专用加速器。借助 UCIe 技术,这款小芯片(chiplet)可以直接集成到 NVIDIA GPU 的封装基板上,从而直接调用该 GPU 的高带宽存储资源及计算能力。为此,NVIDIA 提供了一款“UCIe 转 NVLink”的桥接小芯片,使得这款基于开放标准的小芯片能够与 NVIDIA 专有的 NVLink 互连架构实现对接。这种混合式的技术方案充分体现了这样一个现实:没有任何一家公司能够独自提供人工智能技术栈中的所有组件。
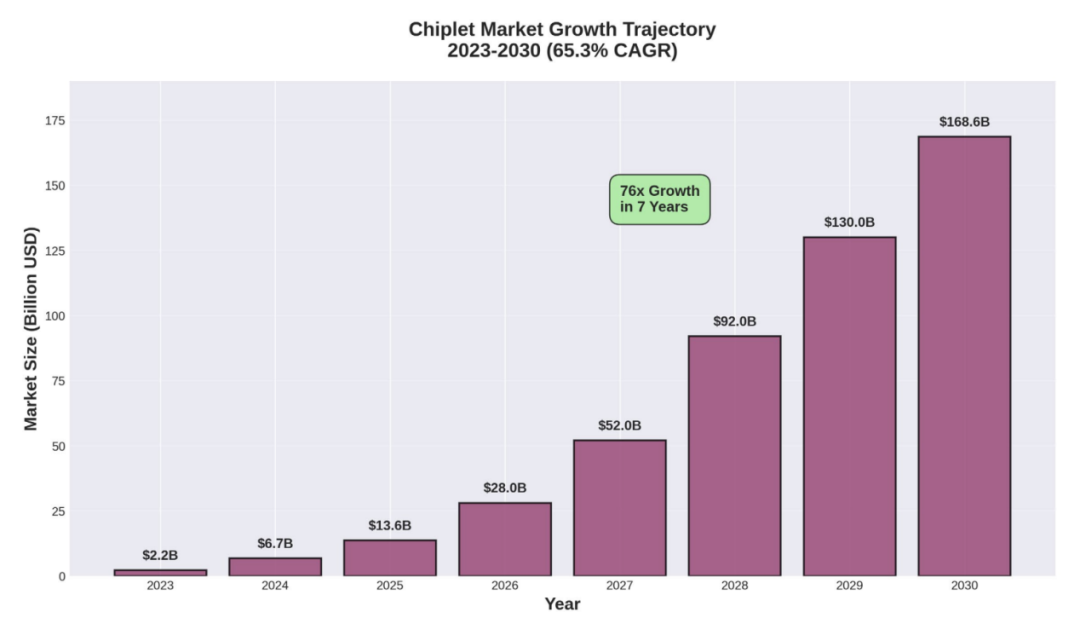
CXL(Compute Express Link)
如果说玻璃构筑了房屋的主体,UCIe 负责连接各个房间,那么 CXL(Compute Express Link)则负责管理其中的资源。具体而言,CXL 旨在解决“内存墙”问题——即处理器运行速度与为其提供数据的内存容量及带宽之间日益扩大的鸿沟。对于 AI 工作负载而言,内存容量往往是限制模型规模的硬性瓶颈。CXL 通过将内存与 CPU 解耦,从而打破了这一制约。
CXL 3.1 与未来的互连架构
CXL 已从点对点链路(CXL 1.0/1.1)演进为真正的交换互连架构(CXL 2.0 及更高版本)。
-
CXL 1.0/1.1:这些早期版本允许 CPU 连接至内存扩展卡(例如 DRAM 驱动器)。虽然这提供了额外的内存容量,但这些内存仍归属于该单一 CPU 所有。
-
CXL 2.0:引入了单级交换和内存池化功能,允许多达 16 个主机同时访问共享内存池中的不同区域。
-
CXL 3.0/3.1:实现了多级交换和互连架构(Fabric)能力,支持非树状拓扑结构(如网状、环状),且节点数量可扩展至 4096 个。CXL 交换机的功能类似于网络交换机,但其服务对象是内存;通过 CXL 交换机,多个主机(包括 CPU 和 GPU)可连接至同一台交换机,同时多个内存模块也可连接至同一台交换机。
这种架构实现了全局织物连接内存(GFAM)功能。单个 GFAM 设备可供多达 4,095 个节点访问,且无需建立直接的主机连接。CXL 3.0 的点对点(Peer-to-Peer)能力允许加速器直接访问存储在 CXL 内存模组中的数据,而无需通过主机 CPU 进行路由,从而显著降低了延迟并减轻了 CPU 的开销。这对 AI 推理工作负载而言尤为宝贵;在此类场景下,KV 缓存的扩展以及受内存带宽限制的操作都能从 CXL 的解耦式内存池中获益,尽管大规模分布式 AI 训练目前仍主要依赖 NVLink 来实现 GPU 之间的通信。
解决“闲置内存”问题
CXL 技术的核心经济驱动力在于消除“闲置内存”(Stranded Memory)问题。在传统的服务器架构中,内存是进行静态配置的。如果一台服务器为了应对特定的“最坏情况”工作负载而配置了 2TB 的内存,但其平均工作负载仅需使用 500GB,那么剩余的 1.5TB 内存就会处于闲置状态——它既消耗电力又占用资金,却无法产生任何实际价值。此外,这部分闲置内存也无法借调给邻近的、正面临内存资源枯竭的服务器使用。据微软公司估算,在 Azure 云平台中,任何时刻都有高达 25% 的内存处于闲置状态。
CXL 技术实现了“内存池化”(Memory Pooling)功能。数据中心架构师无需为每台服务器都配置 2TB 的内存,而是可以仅为服务器配置 500GB 的本地内存,并将一个容量高达 100TB 的共享内存池部署在机架内的专用共享内存设备中。当某台服务器需要为突发性的 AI 计算任务获取更多内存资源时,它可以向该内存池发出请求。随后,CXL 互连架构管理器(CXL Fabric Manager)会动态地为其分配所需的内存。一旦该计算任务完成,所分配的内存便会被归还至内存池中。据业界估算,这种内存解耦(Disaggregation)模式可将整体内存需求降低 7% 至 10%,进而使服务器的综合成本降低 4% 至 5%,对于超大规模数据中心运营商(Hyperscalers)而言,这有望每年节省数亿美元的巨额开支。
硬件实现
一、CXL 设备
各大内存厂商已发布了先进的硬件产品,以支持这一愿景的实现。
1、三星 CMM-B 与 CMM-D
三星推出了 CMM-D(CXL 内存模组 – DRAM)65,这本质上是一条支持 CXL 协议的 DRAM 内存条。该公司还发布了 CMM-B(Box)66,这是一款机架级内存设备。CMM-B 可容纳多个 CMM-D 模组(采用 E3.S 外形规格),在 4U 机架式机箱中最多可容纳 24 个,并可同时连接多达三台主机。它充当着一个集中式的内存资源池。
为了确保该方案的可用性,三星开发了 Samsung Cognos Management Console (SCMC)67;这是一款软件,能够独立于所连接的服务器之外,对内存进行动态分配管理。此外,三星还与 Red Hat68 开展了深度合作,以确保 Red Hat Enterprise Linux (RHEL) 9.3 版本中包含原生的 CXL 驱动程序,从而无需重写应用程序即可识别并利用这种分层内存。CMM-D 在系统中呈现为一个“zero CPU”的 NUMA 节点,使现有的、具备 NUMA 感知能力的应用程序能够以透明的方式利用该内存池资源。
2、SK海力士 Niagara 与计算内存
SK海力士凭借 Niagara 2.069 进一步拓展了这一概念。这是一个池化内存平台,允许多个主机(包括 CPU 和 GPU)高效共享大型内存池,从而最大限度地减少闲置内存(stranded memory)的浪费。此外,该公司还推出了 CMM-Ax(CXL 内存模块-加速器)70,该产品的前身为 CMS(计算内存解决方案)。这些模块不仅仅用于存储数据,还能直接对数据进行处理。
在 AI 和大数据应用场景中,CPU 往往需要耗费大量时间,对存储在内存中的海量数据集执行机器学习和数据过滤等操作。SK海力士的 CMM-Ax 模块内置了逻辑单元,可以直接在内存模块内部执行 KNN(K近邻)分类、数据过滤及负载均衡等任务;在特定计算场景下,其性能可达到“数十个 CPU 核心协同工作时的数倍”。该公司已成功展示了 CMM-Ax 与 Meta 公司的 Faiss 向量搜索引擎以及 SK 电讯(SK Telecom)的 Petasus AI 云平台的集成应用。由于仅需将相关的计算结果回传至 CPU,此举不仅降低了 CXL 链路上的数据流量,还能释放出宝贵的 CPU 计算周期,使其能够专注于处理更为复杂的任务。
系统级封装(SOP)集成
2026年路线图的核心特征在于这些技术的融合。其中,“系统级封装”(SoP)正是玻璃基板、UCIe和CXL协同运作所结出的硕果。2026年路线图的另一大特征,则是这些技术的集成。系统级封装(SoP)将玻璃基板、UCIe和CXL整合进了一个统一的架构之中。
2026年AI超级芯片的解剖结构
试想一下2026年最尖端AI处理器的架构。它已不再是传统意义上的“芯片”;其架构与传统的单片式设计有着本质的区别。
1. 基底:整个组件置于玻璃基板之上。这是一种新兴技术,能够提供所需的尺寸稳定性,从而支持安装多个小芯片(chiplets),且不会出现有机基板在大尺寸应用中常见的翘曲问题。玻璃基板不仅支持封装尺寸突破 100mm × 100mm 的限制,还具备支持未来集成光波导技术的潜力。
2.逻辑单元:计算功能被拆分为多个iles。其中部分为“性能tiles”(采用 Intel 18A 工艺节点),专司计算任务;另一些则为“基础tiles”(采用 Intel 3 工艺节点),主要承载 SRAM 缓存及 I/O 路由功能。这些瓦片通过 Intel 独有的混合键合技术——Foveros Direct 3D——实现垂直堆叠,该技术具备小于 10µm 的极精细间距;而在水平方向上,它们则通过 UCIe 3.0 互连走线实现连接,支持高达 64 GT/s 的数据传输速率。
3.存储方面:HBM4堆栈紧邻逻辑单元,每堆栈可提供高达 2 TB/s 的带宽。然而,仅靠封装内存储是不够的。该封装还集成了 CXL 3.0接口,可通过(潜在的)新兴光互连技术连接至机架级内存池,从而使该加速器能够访问数 TB 的共享内存,以用于训练大参数模型。
热管理与电源管理
这种集成融合带来了极高的功率密度。在近期,人们普遍探讨的先进加速器封装——通常包含大型逻辑芯片块(logic tiles)和多层高带宽内存(HBM)堆栈——其功耗范围已达到 1,500W 至 2,000W82。一些前瞻性的技术路线图甚至预测,在 2030 年代后期,功耗将进一步攀升至数千瓦级;针对 2035 年左右的极端应用场景,甚至有关于 15 kW 级超高功耗模块的探讨82。正是在这一背景下,玻璃基板所具备的优异耐高温特性83显得尤为关键。玻璃材料在高达 250°C 至 400°C 的高温环境下仍能保持近乎完美的平整度,而有机材料在承受热应力时则容易发生形变或分层剥离。
得益于这种极高的尺寸稳定性,工程师能够放心地采用更为激进的散热方案——例如直接接触式液冷或浸没式冷却——而无需担忧基板会因此丧失其机械结构的完整性。然而,鉴于玻璃材料本身的导热系数较低,可能需要引入创新的散热路径(例如嵌入式流体通道),方能有效地将热量从芯片的热点区域迅速导出。
未来展望:光子集成
该技术路线图的下一步——即在2026至2028年的时间窗口内已初现端倪的阶段——将是光子技术的全面集成。鉴于电信号(即使是通过CXL协议传输)在长距离传输时会面临电阻和散热难题,且铜导线已无法在超过数米的距离上可靠地承载高速信号,因此“同封装光学”(Co-Packaged Optics,简称CPO)技术便显得至关重要。
首批针对网络交换机的CPO部署预计将于2025至2026年间落地,主要通过NVIDIA的Quantum-X和Spectrum-X Photonics平台实现;这些平台均基于台积电(TSMC)的COUPE平台,采用了硅光子技术。展望未来,玻璃基板有望成为推动下一代光子集成技术实现突破的关键支撑。康宁公司(Corning)与佐治亚理工学院(Georgia Tech)的联合研究已证实,光波导可直接嵌入至玻璃基板的核心层中;康宁公司也已在2025年的OFC大会上,对这项玻璃波导技术进行了前瞻性展示。
这意味着前文所探讨的CXL互连链路,最终可能会从传统的铜导线传输方案向光传输方案实现过渡。Ayar Labs公司推出的UCIe光学小芯片(Optical Chiplet)方案,目前已能通过光信号承载CXL、NVLink及其他各类通信协议。此举有效地打破了带宽与传输距离之间的固有瓶颈:光学I/O接口的传输距离可延伸至100米(若需超长距离传输,甚至可达数公里),从而使分散部署的GPU集群能够像集成于单一封装内部一样协同运作,进而为构建机架级乃至最终实现跨机架的AI计算架构奠定坚实基础。
结论
2026年的半导体产业格局呈现出一个根本性的悖论:若要持续提升性能,该行业必须摒弃仅专注于晶体管微缩的单一策略。“无微缩的性能扩展”(Scaling Without Shrinking)时代已然降临。2026年的半导体格局反映了行业优先重点的转变:为了持续提升性能,业界已将关注点从单纯的晶体管微缩拓展至更广阔的领域。通过将封装技术从有机材料的局限中解耦(引入玻璃基板),将功能模块从单片集成芯片中解耦(通过UCIe标准),并将内存从主板中解耦(通过CXL标准),该行业找到了一条绕开光刻技术瓶颈的全新路径。这一策略催生了一类新型的“封装系统”(System-on-Package)计算机——它们具备模块化、灵活性强的特性,且高度适用于人工智能(AI)工作负载。
未来的技术发展路线图不再是一条直指“零纳米”极限的单一路线;取而代之,它已向玻璃基板、光子技术及开放式标准等领域全面拓展。通过将封装技术从有机材料的局限中解耦(引入玻璃基板),将功能模块从单片集成芯片中解耦(通过UCIe标准),并将内存从主板中解耦(通过CXL标准),该行业找到了一条绕开光刻技术瓶颈的全新路径。这一策略催生了一类新型的“封装系统”计算机——它们具备模块化、灵活性强的特性,且高度适用于人工智能(AI)工作负载。
如今,半导体的技术发展路线图已不再局限于单纯的晶体管密度提升,而是进一步延伸至先进封装、光子技术以及标准化的芯粒(Chiplet)互连技术等更广泛的领域。
*免责声明: 文章内容系作者个人观点 转载仅为了传达一种不同的观点, 如果有任何异议,欢迎联系删除。
文章来源: 半导体行业观察
- 还没有人评论,欢迎说说您的想法!



