

对于人工智能模型而言,规模很重要。
尽管一些人工智能专家警告说,大规模语言模型(LLM)的性能提升正在逐渐递减,但各公司仍在不断推出规模越来越大的人工智能工具。Meta 最新发布的Llama模型就拥有惊人的2 万亿个参数。
随着模型规模的增大,其功能也随之增强。但同时,模型的能耗和运行时间也会增加,从而导致碳排放增加。为了缓解这些问题,人们开始使用规模更小、功能更弱的模型,并尽可能使用精度较低的模型参数。
但还有另一种方法,既能保持庞大模型的高性能,又能减少运行时间和能耗。这种方法的关键在于善用大型人工智能模型中的零值(This approach involves befriending the zeros inside large AI models)。
对于许多模型而言,大多数参数(权重和激活值)实际上为零,或者非常接近于零,以至于可以将其视为零而不会损失精度。这种特性被称为稀疏性(sparsity)。稀疏性为节省计算资源提供了绝佳的机会:无需浪费时间和精力进行零的加法或乘法运算,这些计算可以直接跳过;也无需在内存中存储大量零,只需存储非零参数即可。
遗憾的是,如今流行的硬件,例如多核CPU和GPU,并不能充分利用稀疏性。为了充分发挥稀疏性的优势,研究人员和工程师需要重新思考并重新架构设计堆栈的每个部分,包括硬件、底层固件和应用软件。
在斯坦福大学的研究团队中,我们开发出了(据我们所知)首个能够高效计算各种稀疏和传统工作负载的硬件。不同工作负载的节能效果差异很大,但平均而言,我们的芯片能耗仅为CPU的1/70,计算速度平均快8倍。为了实现这一点,我们必须从零开始设计硬件、底层固件和软件,以充分利用稀疏性。我们希望这仅仅是硬件和模型开发的开端,未来将实现更节能的人工智能。
什么是稀疏性?
神经网络及其输入数据都以数字数组的形式表示。这些数组可以是一维的(向量)、二维的(矩阵)或更高维的(张量)。稀疏的向量、矩阵或张量主要由零元素构成。稀疏程度各不相同,但当任何类型的数组中零元素占比超过 50% 时,就可以利用针对稀疏性的计算方法。相反,如果一个对象不稀疏——也就是说,与元素总数相比,它的零元素很少——则称为稠密对象。
稀疏性可以是天然存在的,也可以是人为诱导产生的。例如,社交网络图本身就是稀疏的。想象一个图,其中每个节点(点)代表一个人,每条边(连接这些点的线段)代表一段友谊。由于大多数人彼此之间并非朋友,因此表示所有可能边的矩阵将主要由零组成。其他流行的AI应用,例如其他形式的图学习和推荐模型,也包含天然存在的稀疏性。
除了自然发生的稀疏性之外,还可以通过多种方式在人工智能模型中引入稀疏性。两年前,Cerebras的一个团队 证明,在 LLM 模型中,可以将高达 70% 到 80% 的参数设置为零,而不会损失任何精度。Cerebras专门在 Meta 的开源 Llama 7B 模型上验证了这些结果,但这些思路也适用于其他 LLM 模型,例如ChatGPT和Claude。
稀疏性论证
稀疏计算的高效性源于两个基本特性:压缩零值(zeros)的能力以及零值本身便捷的数学性质。稀疏计算中使用的算法及其专用硬件都充分利用了这两个基本概念。
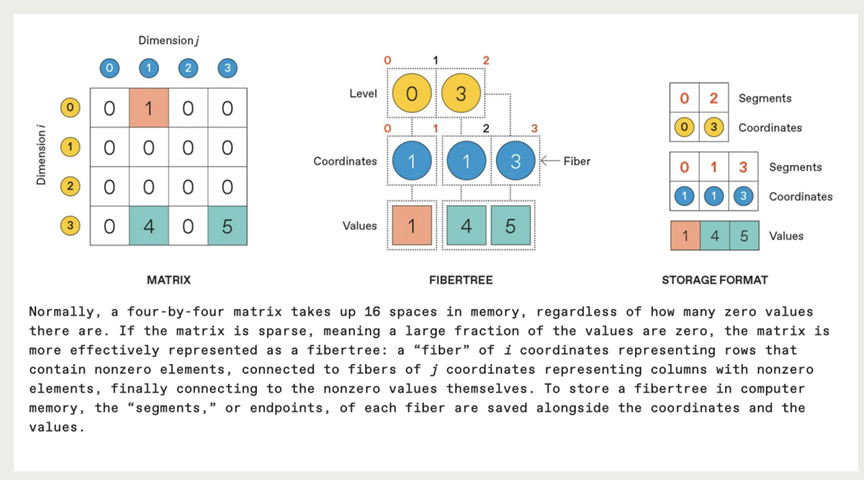
首先,稀疏数据可以被压缩,从而更有效地利用内存,以“稀疏”方式存储——也就是使用稀疏数据类型。压缩还能提高处理大量数据时的数据传输能耗。举例来说,假设有一个 4×4 的矩阵,其中包含三个非零元素。传统上,这个矩阵会直接存储在内存中,占用 16 个空间。这个矩阵也可以被压缩成稀疏数据类型,去掉零元素,只保留非零元素。在我们的例子中,压缩后的矩阵只占用 13 个内存空间,而未压缩的稠密版本则需要 16 个空间。随着稀疏度和矩阵大小的增加,内存节省也会增加。
除了实际数据值之外,压缩数据还需要元数据(metadata)。非零元素(nonzero elements )的行和列位置也必须存储。这通常被视为一种“fibertree”:包含非零元素的行标签被列出并链接到非零元素的列标签,然后这些列标签又链接到存储在这些元素中的值。
在内存中,情况会变得更加复杂:必须存储每个非零值的行标签和列标签,以及指示预期有多少个此类标签的“段”,以便将元数据和数据清楚地区分开来。
在稠密、非压缩矩阵数据类型中,可以逐个或并行访问值,并且可以直接用简单的公式计算其位置。然而,访问稀疏、压缩数据中的值需要先查找行索引的坐标,然后利用该信息“间接”查找列索引的坐标,最终才能找到目标值。由于稀疏数据值的实际位置可能存在很大的随机性,这些间接查找的结果可能与数据密切相关,并且需要动态分配内存查找操作。
其次,零的两个数学特性使得软件和硬件可以省略大量计算。任何数乘以零的结果都是零,因此无需实际进行乘法运算。任何数加上零的结果也总是该数本身,因此也无需进行加法运算。
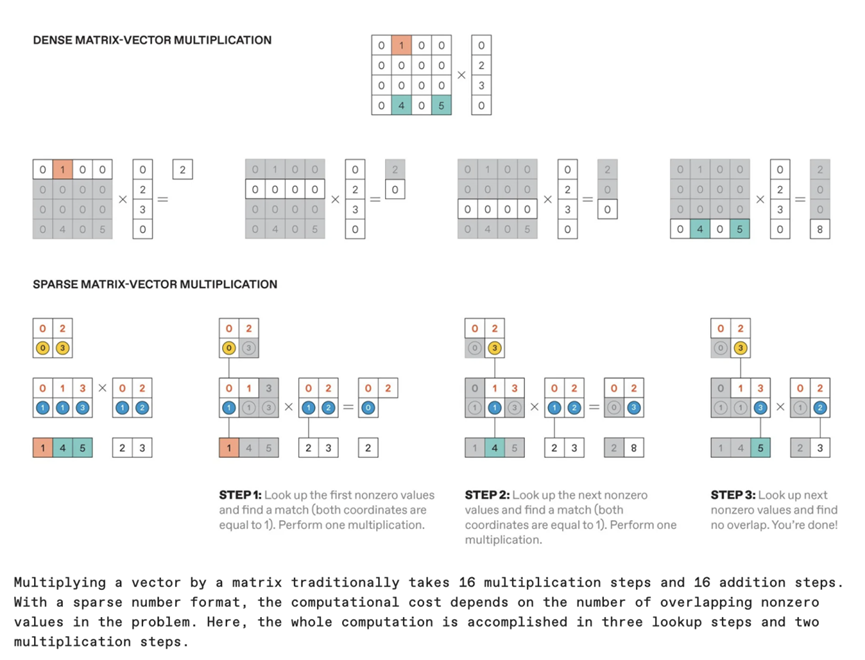
在矩阵向量乘法中,这是人工智能工作负载中最常见的运算之一,除了涉及两个非零元素的运算之外,所有其他计算都可以直接跳过。例如,考虑前面例子中的 4x4 矩阵和一个包含四个数字的向量。在密集计算中,向量中的每个元素都必须与其每一行中对应的元素相乘,然后将所有乘积相加才能得到最终的向量。在这种情况下,需要进行 16 次乘法运算和 16 次加法运算(或 4 次累加运算)。
在稀疏计算中,只需考虑向量的非零元素。对于每个非零向量元素,可以使用间接查找法找到对应的非零矩阵元素,然后仅对这些元素进行乘法和加法运算。在本例中,只需执行两次乘法运算,而不是通常的16次。
GPU和CPU的问题
遗憾的是,现代硬件并不适合加速稀疏计算。例如,假设我们要执行矩阵向量乘法。最简单的情况是,在单个 CPU 核心上,向量中的每个元素都会依次相乘,然后写入内存。这种方法速度很慢,因为一次只能进行一次乘法运算。因此,人们会使用支持向量运算的 CPU 或 GPU。有了这些硬件,所有元素都可以并行相乘,从而大大提高应用程序的运行速度。现在,假设矩阵和向量都包含极其稀疏的数据。向量化的 CPU 和 GPU 会将大部分资源用于执行乘以零的操作,进行完全无效的计算。
新一代GPU能够利用硬件的稀疏性,但仅限于一种称为结构化稀疏性的特定类型。结构化稀疏性假设每四个相邻参数中至少有两个为零。然而,某些模型更受益于非结构化稀疏性——即任何参数(权重或激活值)都可以为零并被压缩,而无需考虑其位置和相邻参数。GPU可以通过软件运行非结构化稀疏计算,例如使用cuSparse GPU库。然而,对稀疏计算的支持通常有限,导致GPU硬件利用率不足,将大量高能耗计算浪费在开销上。
在软件中进行稀疏计算时,现代 CPU 可能比 GPU 计算更合适,因为它们的设计更加灵活。然而,CPU 上的稀疏计算常常会受到用于查找非零数据的间接查找的瓶颈。CPU 的设计是基于预期从内存中获取的数据进行“预取”,但对于随机稀疏数据,这个过程往往无法从内存中获取正确的数据。在这种情况下,CPU 必须浪费周期来调用正确的数据。
苹果公司率先在其 A14 和 M1 芯片的预取器中支持一种名为指针数组访问模式的方法,从而加速了这些间接查找。尽管预取技术的创新使苹果 CPU 在稀疏计算方面更具竞争力,但由于 CPU 架构需要处理通用计算,因此仍然存在专用稀疏计算架构所没有的根本性开销。
其他公司也在开发加速稀疏机器学习的硬件,例如 Cerebras 的晶圆级引擎 (Wafer Scale Engine)和Meta 的训练与推理加速器 (MTIA)。晶圆级引擎及其对应的稀疏编程框架在 LLM 模型上展现出了惊人的稀疏性,最高可达 70%。然而,该公司的硬件和软件解决方案仅支持权重稀疏性,不支持激活稀疏性,而激活稀疏性对于许多应用至关重要。MTIA 的第二版声称其稀疏计算性能比MTIA v1提升了七倍。但是,目前公开的关于 MTIA v2 稀疏性支持的信息仅限于矩阵乘法,而非向量或张量。
尽管矩阵乘法在大多数现代机器学习模型中占据了大部分计算时间,但对其他部分进行稀疏性支持也至关重要。为了避免在稀疏数据类型和稠密数据类型之间来回切换,所有操作都应该是稀疏的。
Onyx
斯坦福大学的研究团队没有采用这些折衷方案,而是开发了一款名为Onyx 的硬件加速器。Onyx从一开始就能充分利用稀疏性,无论数据是结构化的还是非结构化的。它是首款同时支持稀疏计算和稠密计算的可编程加速器,能够加速这两个领域中的关键运算。
要了解 Onyx,有必要了解什么是粗粒度可重构阵列 (CGRA:coarse-grained reconfigurable array),以及它与更熟悉的硬件(如 CPU 和现场可编程门阵列 ( FPGA ))有何不同。
CPU、CGRA 和 FPGA 代表了效率和灵活性之间的一种权衡。CPU 的每个逻辑单元都针对特定功能而设计,并能高效地执行这些功能。另一方面,由于FPGA的每个比特都是可配置的,因此这些阵列非常灵活,但效率却很低。CGRA 的目标是在保持 CPU 效率的同时,实现 FPGA 的灵活性。
CGRA 由高效且可配置的单元组成,通常是内存和计算单元,这些单元针对特定的应用领域进行了专门设计。这是此类阵列的关键优势:程序员可以对 CGRA 的内部结构进行高级重新配置,使其比 FPGA 更高效,比 CPU 更灵活。

Onyx 由灵活可编程的处理单元 (PE:processing element) 和存储单元 (MEM) 组成。存储单元用于存储压缩矩阵和其他数据格式。处理单元则直接对压缩矩阵进行运算,从而消除所有不必要和低效的计算。
Onyx 编译器负责将软件指令转换为 CGRA 配置。首先,输入表达式(例如稀疏向量乘法)被转换为抽象内存和计算节点的图。在本例中,内存用于存储输入向量和输出向量,计算节点用于查找非零元素的交集,计算节点用于执行乘法运算。编译器会确定如何将抽象内存和计算节点映射到CGRA 上的MEMS和 PE,以及如何将它们连接起来以便它们之间可以传输数据。最后,编译器生成配置 CGRA 以实现所需功能所需的指令集。
由于 Onyx 是可编程的,工程师可以将许多不同的操作(例如向量-向量元素乘法)或人工智能中的关键任务(例如矩阵-向量或矩阵-矩阵乘法)映射到加速器上。
我们通过计算能耗与计算时间的乘积(称为能量延迟积,EDP)来评估硬件的效率提升。该指标体现了速度和能耗之间的权衡。如果只追求能耗最小化,会导致设备速度非常慢;而如果只追求速度最小化,则会导致设备面积大、功耗高。
与使用专用稀疏库的CPU(我们使用的是 12 核Intel Xeon CPU)相比,Onyx 的能耗延迟积最高可提升 565 倍。Onyx 还可以配置为加速常规的密集型应用程序,类似于 GPU 或TPU 的工作方式。如果计算是稀疏的,Onyx 会配置为使用稀疏原语;如果计算是密集的,Onyx 会重新配置以利用并行性,类似于 GPU 的工作方式。这种架构是朝着在同一芯片上加速稀疏和密集计算的单一系统迈出的重要一步。
同样重要的是,Onyx 能够催生全新的算法思维。稀疏加速硬件不仅能提升人工智能的性能和能效,还能帮助研究人员和工程师探索有望大幅提升人工智能的新算法。
稀疏性的未来
斯坦福大学的团队已经在研发基于 Onyx 的下一代芯片。除了矩阵乘法运算之外,机器学习模型还会执行其他类型的数学运算,例如非线性层、归一化、softmax 函数等等。该团队正在下一代加速器和编译器中添加对所有这些计算的支持。由于稀疏机器学习模型可能同时包含稀疏层和密集层,我们也在努力更高效地将密集和稀疏加速器架构集成到芯片上,从而实现不同数据类型之间的快速转换。此外,该团队还在探索如何通过更有效地分解稀疏数据来管理内存限制,以便在多个稀疏加速器芯片上运行计算。
该团队也在研发能够预测我们这类加速器性能的系统,这将有助于设计更适合稀疏人工智能的硬件。从长远来看,我们感兴趣的是,人工智能计算中高度稀疏性是否会在更多模型类型中得到应用,以及稀疏加速器能否被更大规模地采用。
构建能够处理非结构化稀疏数据并充分利用零值的硬件仅仅是开始。有了这套硬件,人工智能研究人员和工程师将有机会探索以新颖且富有创意的方式利用稀疏性的新模型和算法。我们认为,这对于应对人工智能日益增长的运行时间、成本和环境影响至关重要。
文章来源: 半导体行业观察
- 还没有人评论,欢迎说说您的想法!



