

最近,韩国半导体工程师学会(ISE)发布了《2026 年半导体技术路线图》,其中谈到了半导体工艺发展到0.2nm的预测,引起了不少关注。但如果只把它当作一份“制程更先进、指标更激进”的技术预测,反而容易忽略它真正想传达的信息。
这份路线图以2025年为起点,展望至2040年,对未来约15年的器件与工艺、人工智能半导体、光互连、无线互连、传感器技术、有线互连、存算一体(PIM)、封装技术及量子计算技术等九大半导体技术发展趋势进行了系统性预测。这并不是一份“更小制程”的路线图,而是一份关于半导体竞争形态正在发生改变的行业判断。
如果说过去的路线图是关于“尺寸”的军备竞赛,那么这份路线图则是关于“范式”的全面重构。让我们穿透0.2nm这个极具冲击力的数字,沿着它给出的九条技术主线,去解析这本长达15年的“未来生存手册”。
器件与工艺技术路线图
半导体产业过去数十年的主线只有一条——持续微缩。通过缩小器件尺寸,芯片在功耗、成本和性能上不断获得红利。最终产品的竞争力,往往体现在更高速度、更高密度、更低功耗、更小体积、更低材料成本,以及更强的系统功能上。
综合 IRDS 的 More Moore IFT(国际重点团队)研究成果,以及 IMEC 在 ITF World 2023 与 2024 上给出的前瞻预测,韩国的路线图试图回答一个核心问题:在大数据、智能移动、云计算与 AI 工作负载持续攀升的背景下,逻辑与存储技术如何在 PPAC(功耗–性能–面积–成本) 约束下继续演进?
以量产级技术为基准,这一技术路线图从2025年起每3年为一个节点,描绘了逻辑与存储器件在未来15 年(至2040年)的可能演进路径,涵盖物理结构、电气特性与可靠性等关键维度。
逻辑技术趋势:从2nm到0.2nm
逻辑器件工艺演进的核心目标始终未变:在更小的工艺间距和更低的工作电压下,维持性能与功耗的有效缩放(Scaling)。然而,随着尺寸不断缩小,一个现实问题愈发突出——寄生效应正在吞噬微缩红利。金属互连、电容耦合、电阻上升,使得负载在整体性能与功耗中的占比持续提高,甚至可能抵消晶体管本身的改进。
这也直接推动了设计范式的转变。
过去,行业主要依赖 DTCO(Design-Technology Co-Optimization,设计-工艺协同优化),通过电路设计来弥补工艺微缩带来的性能损失;而如今,优化的边界被进一步拉大,演进为 STCO(System-Technology Co-Optimization,系统-工艺协同优化)——优化对象不再局限于单一芯片,而是扩展至 Chiplet、先进封装、存储层级、互连结构,乃至整个系统架构。
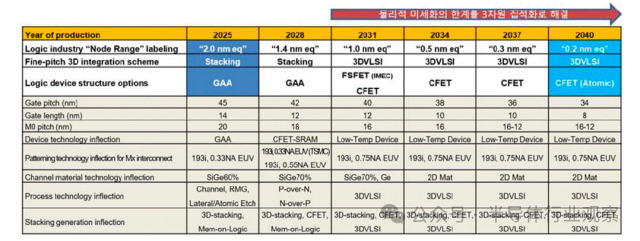
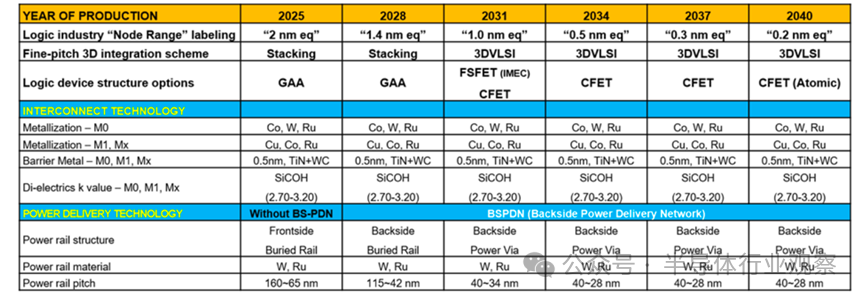
根据器件结构与关键工艺变量的路线图预测,逻辑器件的“名义节点”将从2025年的 2nm 级,推进至2031年的1nm 级,并在2040年前后逼近0.2nm量级。微缩的关键变量主要集中在四个方面:三维栅极结构与间距、金属布线Pitch、栅极长度(Lg)、三维层叠与顺序集成能力。
逻辑器件的器件结构及工艺技术核心变量
下图显示了器件结构的演进趋势。自 2025 年起,逻辑晶体管的主流结构将逐步从 FinFET 转向 GAA(Gate-All-Around),FinFET 及 GAA 架构利用完全耗尽通道和完全反转通道(体反转)。进一步地,FS-FET(Fork-Sheet FET) 通过在纳米片之间加入绝缘层来分离 N 器件和 P 器件,可大幅缩小器件尺寸。虽然在2031年左右引入 0.75NA EUV 可使线宽比现有的 0.33NA EUV 缩小 2.3 倍,但物理微缩预计将趋于饱和。预计将通过 PMOS 和 NMOS 的三维集成,即称为 CFET(互补场效应晶体管)的 3D VLSI 方向来提升器件性能。预计 CFET(Complementary FET) 将进化为 P 器件堆叠在 N 器件之上的 3D 形式。
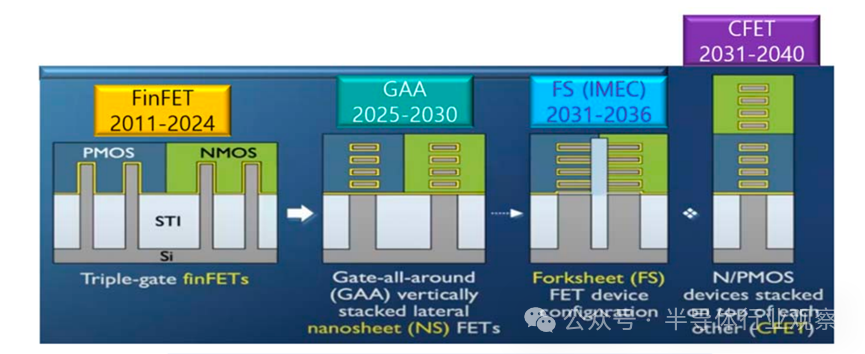
晶体管结构的演进(来源:ITF World 2023,IMEC)
但CFET也引入了新的技术门槛,低温工艺成为刚需,以避免上层器件制造对下层结构造成热损伤。在移动终端和边缘计算快速普及的背景下,降低工作电压(Vdd) 已成为不可逆趋势。为了在低电压条件下维持性能,近年来逻辑器件研发的重点集中在几项关键技术上:通道晶格应变(促进迁移率)、HKMG(高k金属栅极)、降低接触电阻及改善静电特性。
进一步的微缩,正在从“器件层面”走向“结构层面”。单片 3D(Monolithic 3D, M3D) 集成,使晶体管得以在同一晶圆上进行垂直堆叠。短期目标仍然是单线程性能提升与功耗降低;而中长期,则将演进为低 Vdd、高并行度、单位体积集成功能最大化的三维架构。
与此同时,3D 混合存储器-逻辑(3D Hybrid Memory-on-Logic)方案,正在成为 AI 与 HPC 的关键突破口。通过 Hybrid Bonding 直接连接逻辑与存储芯片,可显著缩短数据路径、降低延迟,并提升系统能效,这对 HBM、AI 加速器、端侧 AI 尤为关键。当然,挑战同样明显:异质芯片键合的良率与可靠性、高功耗器件(如 GPU + HBM)的散热路径设计。
在 2025 年至 2040 年路线图预测的 6 个技术节点中,随着 2nm 级以下逻辑器件微缩的推进,寄生元件导致的负载占比增加,受性能和功耗方面的负面影响,工作电压(0.5V~0.4V)不会有大幅改善,但跨导(Transconductance)等模拟特性将得以维持。
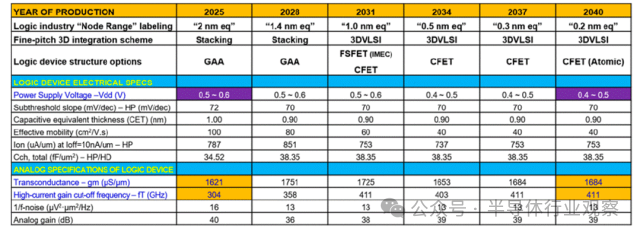
逻辑器件技术路线图
在 2nm之后,金属布线成为限制性能的“第二战场”。行业需要同时满足三项几乎相互矛盾的目标:更低电阻、更低介电常数、更高可靠性。这对材料体系、刻蚀工艺和大马士革(Damascene)集成精度提出了极高要求。高深宽比结构下的RC退化,使得先进计量、原位监测与实时工艺控制成为不可或缺的基础能力。
在供电架构上,一个重要的变革正在发生——背面供电(Backside Power Delivery)。通过将电源网络从芯片正面移至背面,可以实现:信号与电源路径解耦/降低 IR Drop 与噪声干扰/提升面积利用率与能效。按照金属布线微缩路线图,背面供电网络(BSPDN) 预计将在 2028 年左右开始导入,并在 2031 年后结合 Power Via 技术,将电源轨间距快速推进至 40nm 级别。
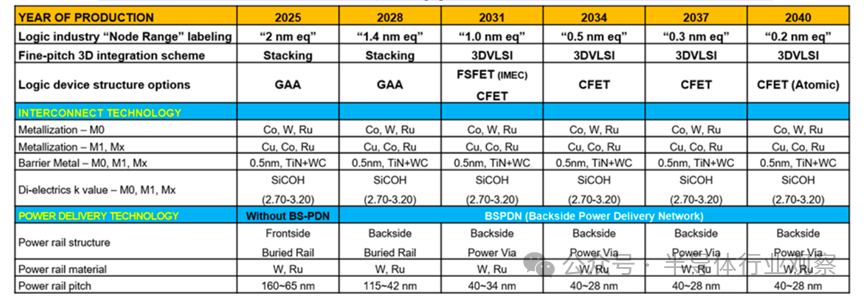
金属布线微缩路线图
存储技术趋势与路线图
如果说过去十年,半导体产业的主角是计算,那么进入 AI 时代后,真正的瓶颈正在快速转移到存储。大模型训练、推理、检索增强(RAG)以及多模态计算,对数据吞吐、访问延迟和能效提出了前所未有的要求。数据中心与 AI 服务器所需要的,不只是“更大的容量”,而是同时具备:高容量 × 高带宽 × 低延迟 × 低功耗,正是在这一背景下,存储器从“配角”转变为决定系统上限的关键角色。
由于DRAM与非易失性存储器(NVM)长期以标准化、独立产品形态引领存储产业演进,ISE的研究重点也主要围绕这两大技术体系展开。嵌入式存储(Embedded Memory)虽然路径相似,但在节点节奏上通常存在一定滞后。
DRAM
DRAM 诞生至今已超过 40 年,却依然是计算系统中不可替代的工作内存。从 PC 的 DDR、移动终端的 LPDDR,到 GPU 的 GDDR、AI 加速器的 HBM,再到高速缓存用的 eDRAM,DRAM 覆盖了几乎所有性能层级。
但问题在于:传统 DRAM单元结构,已经难以继续按原路径微缩。
根据技术路线图预测,DRAM 单元结构正在发生根本性变化(如下图):单元晶体管将从传统结构,演进为垂直通道晶体管(VCT);存储阵列将逐步引入堆叠型 DRAM(Stacked DRAM);单元面积从 6F² 向 4F² 极限逼近。更具颠覆意义的是,CBA(CMOS Bonded to Array)技术开始浮出水面——通过混合键合,将 CMOS 外围电路直接与存储阵列集成,有望突破传统“阵列—外围”分离架构的效率瓶颈。
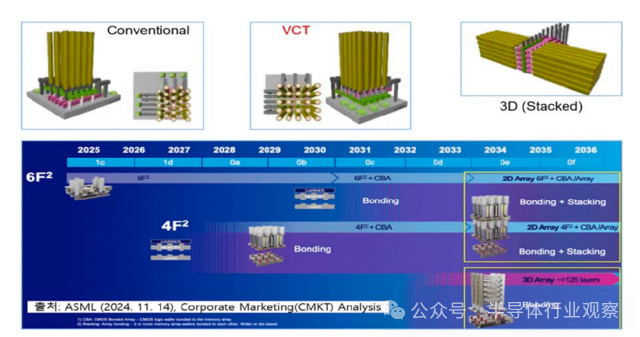
在DRAM的技术演进过程中,双功函数字线、单侧电容器工艺以及埋入式通道 S/A 晶体管已应用于 DRAM 产品中,EUV光刻技术也已开始正式投入应用。为了降低字线和位线的电阻并改善工艺,目前正在研发包括钌(Ru)、钼(Mo)在内的多种新型材料。然而,尽管付出了这些努力,预计基于BCAT(埋入式通道阵列晶体管)的DRAM 单元,微缩极限大约停留在7–8nm。
DRAM技术路线图
为了突破平面 DRAM 的物理天花板,行业正在同步推进多条探索路径:High-NA EUV 的引入、X-DRAM 等 3D DRAM 架构、4F² 单元与无电荷存储 DRAM(Capacitorless DRAM)、电路级与运行机制优化(如更精细的时钟控制)。与此同时,DRAM 工艺的“长期作业清单”也在不断拉长:单元持续微缩、外围电路引入 HKMG、字线/位线新材料(Ru、Mo 等)、更高质量的高 k 电容介质、面向 3D DRAM 的工艺稳定性控制。从中长期看,高容量混合键合 DRAM 芯片,以及高层数 HBM 的晶圆级封装能力,正逐步成为竞争分水岭。
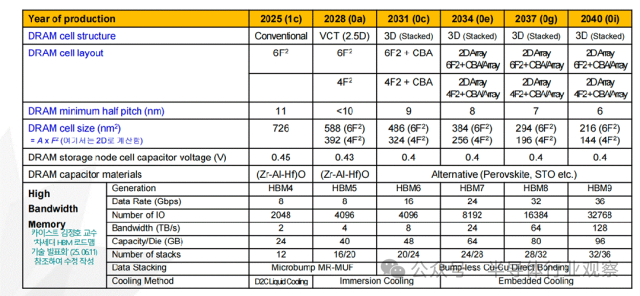
随着 AI训练规模指数级放大,HBM(高带宽存储器)成为增长最快的存储细分市场。它通过多颗 DRAM Die 的垂直堆叠,实现了高带宽、低功耗、近计算的数据供给模式。HBM预计将从2025 年 12 层、2TB/s 带宽,发展至2031年20 层、8TB/s 带宽,并在2040年达到30层以上、128TB/s的带宽水平(上图)。HBM 的核心技术挑战集中在:TSV 工艺与良率、均匀供电与功耗管理、热路径与散热、微凸点 / 混合键合接口、I/O 数量持续扩展。进一步看,HBM 的意义已经超出“存储器件”本身。要真正突破冯·诺依曼瓶颈,PIM(存内处理)、CIM(存内计算)、AIM(加速器内存)等新范式,正围绕 HBM与GDDR架构同步推进。同时,CXL存储器也被视为数据中心级别不可或缺的关键拼图。
NVM:Flash还在长高,但路越来越窄
非易失性存储器的应用跨度极大,从 Kb 级嵌入式系统到 Tb 级数据中心,其技术路径也高度分化。
Flash存储基于 1T 单元,在二维平面下几乎无法继续提升密度。真正让NAND走到今天的,是3D堆叠。当前3D NAND 的核心难题,并不在电学原理,而在制造本身:超高深宽比深孔刻蚀、多层介质与多晶硅沉积、晶圆翘曲(Warpage)控制、高精度计量与缺陷监测。3D-NAND 技术方面,产业界已经给出清晰节奏:321 层闪存已于 2025 年开始量产;预计 2028 年后可实现 600 层,2031 年左右实现 1000 层。若能应用工艺微缩及 3D 混合键合技术,预计到 2040 年甚至有望达到 2000 层。但层数越高,字线接触结构的面积开销也随之放大。因此,Word Line Pitch 必须快速压缩,近期已逼近 40nm 以下。
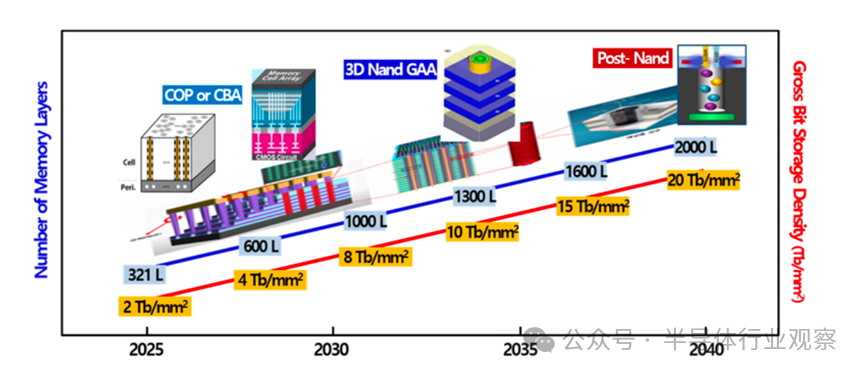
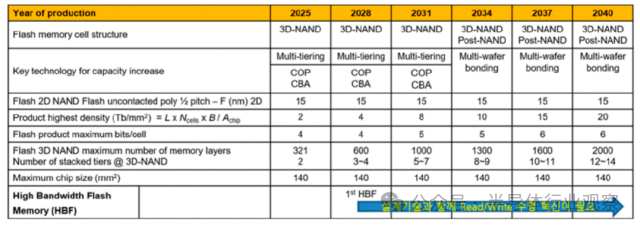
在单元层面,QLC 已全面商用,PLC 也在推进之中。但每增加一bit,意味着:编程/读取时间更长、电平间隔更窄、可靠性压力更大,这是一场典型的性能—成本—可靠性三方博弈。
下一代非易失性存储
除了 Flash,业界也在持续探索不依赖电荷存储的新型 NVM,包括 FeRAM、MRAM、PCM、ReRAM 等。但要取代现有器件,在技术上仍存在大量有待解决的问题。
-
FeRAM / FeFET:依托 HfO₂ 铁电材料,有望实现低功耗、极速的类 Flash 1T 存储,尤其适合嵌入式场景。
-
STT-MRAM:难以在短期内取代大容量 NAND,但在嵌入式 NOR 替代上潜力明确。
-
NOR Flash:由于成熟、稳定、耐高温焊接,仍将在嵌入式系统中长期存在。
-
3D Cross Point / SCM:通过 BEOL 工艺实现多层堆叠,在吞吐量、能效和成本之间取得平衡。
在这些方案中,PCM 被认为是缩放潜力最均衡的路线,而 ReRAM 则仍需克服一致性与波动性问题。
人工智能半导体路线图
AI/ML 的快速发展,直接催生了一个规模庞大的专用计算硬件市场。预计到 2025 年,AI 相关计算将占全球计算需求的约 20%,对应数百亿美元级别的市场规模。从硬件角度看,当前主流 AI/ML 平台主要包括以下几类:CPU、GPU、ASIC、数字 ASIC 加速器、CIM(存内计算)、模拟 ASIC 加速器。
人工智能半导体技术可分为训练和推理两类,其性能表现会随着所采用的硬件和计算精度而呈现出较大的差异。用于训练的计算能力预计将从 2025 年的 0.1~10 TOPS/W,发展到 2040 年的 5~1000 TOPS/W;用于推理的计算能力预计将从 2025 年的 0.1~10 TOPS/W,提升至 2040 年的 1~100 TOPS/W。然而,这一趋势是基于当前计算精度假设得出的,在未来若出现新的精度形式,预测数值可能会发生变化。总体而言,所需且可实现的计算能力预计将根据具体应用进行优化并呈现出不同的水平。
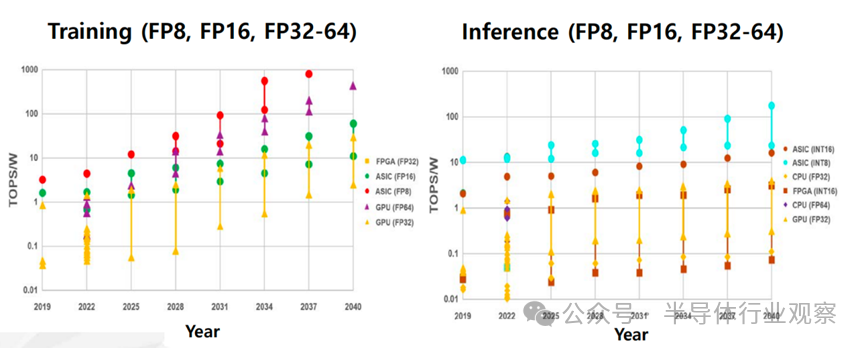
训练和推理用硬件的计算效率发展趋势
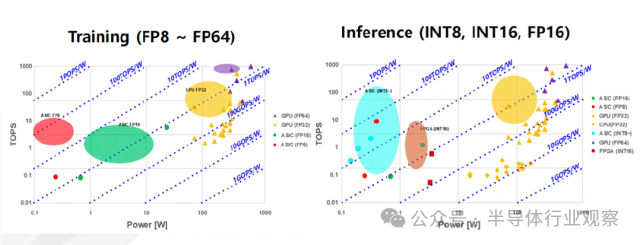
训练和推理用硬件的性能与系统功耗
光连接半导体路线图
在超连接技术体系中,数据的生成、传输与处理能力正逐渐成为决定系统上限的关键因素。随着人工智能(AI)与高性能计算(HPC)规模持续扩张,传统依赖铜互连的电连接方式,正日益暴露出在带宽、功耗、延迟与系统复杂度方面的瓶颈。
在这一背景下,光连接(Optical Interconnect) 被视为突破互连瓶颈的核心技术路径之一。它不仅已广泛应用于现有数据中心内部与数据中心之间的高速通信,还在 AI 与 HPC 驱动的云计算系统中,承担着超高速大规模数据流动的基础设施角色,并逐步向数据生成、协同计算与实时分析等环节延伸。
从更长远的视角看,光连接的应用边界正在持续扩展:面向物联网(IoT)的光传感与边缘连接,光纤到户(FTTH),汽车、航空航天、医疗与工业自动化,自由空间光互连(FSOI)、LiFi 等新型通信方式以及与量子计算系统的深度融合。同时,结合先进半导体器件与封装工艺,将光器件与电子器件在更紧密的尺度上集成,也被认为是光连接技术实现跨代跃迁的重要方向。
当前,光连接最直接的价值在于克服铜互连的物理极限。在高频高速条件下,铜互连不可避免地面临信号衰减、串扰、功耗上升、散热困难以及系统运营成本上升等问题。相比之下,光连接在带宽密度、传输距离和能效方面具有天然优势。
最初,光连接主要应用于局域网、无线通信基站、数据中心之间的长距离通信(>40 km),以及数据中心内部系统之间的互连。近年来,随着 AI 与 HPC 对数据吞吐需求呈指数级增长,光连接开始向计算单元内部以及计算单元之间延伸,成为支撑算力扩展的关键基础设施。
在光连接半导体技术路线图中,数据中心被视为最核心的应用起点。围绕这一场景,光连接技术通常从两个维度进行划分:按系统结构可分为系统内部光连接(Inside-of-Rack)、系统间光连接(Outside-of-Rack);按传输距离可细分为XSR(<1 m)、SR(<100 m)、DR(<500 m)、FR(<2 km)。不同距离与系统形态,对材料、器件、封装与系统架构提出了截然不同的要求。
无论具体实现形式如何,光连接的本质都是通过电–光与光–电转换实现高速数据传输。围绕这一核心,当前的技术演进主线可以概括为 CPO(Co-Packaged Optics)。在实际产品中,通常根据系统边界将其区分为两类:
-
Inside-of-Rack CPO:用于系统内部,替代 PCB 上的铜互连
-
Outside-of-Rack 可插拔式收发器/交换机:用于系统之间连接
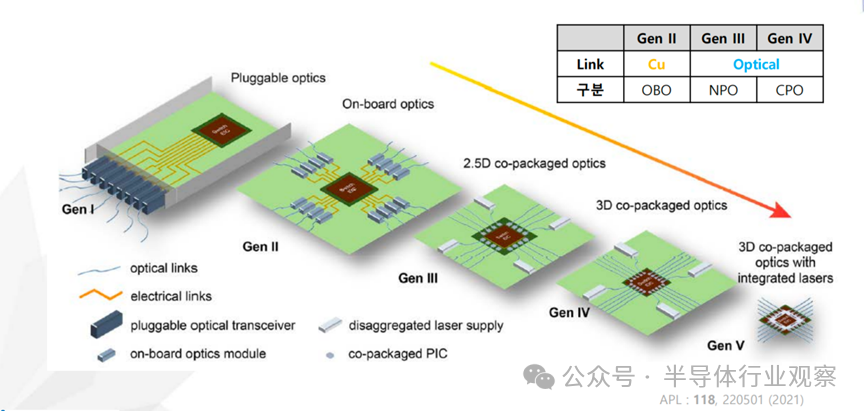
第一代:铜互连为主,光作为补充
在早期架构中,计算器件间的数据主要通过 PCB 上的铜互连传输。随着速率提升,信号失真、串扰与延迟问题愈发严重,需要引入 Retimer 或 DSP 才能勉强维持性能,导致系统功耗、成本与复杂度显著上升。
第二代:OBO 缓解问题,但仍未根治
通过缩短铜互连长度、引入 OBO(On-Board Optics),可在一定程度上降低损耗与功耗。但在 >100 Gbps/lane 的速率需求下,铜互连的物理限制仍然存在。
第三代:NPO,光靠近计算
NPO(Near-Packaged Optics) 通过将光引擎以可插拔或半固定方式布置在靠近计算器件的位置,用光互连取代 PCB 上的高速铜线。目前,基于 VCSEL 的多模方案正在通过国际联合研究持续推进。
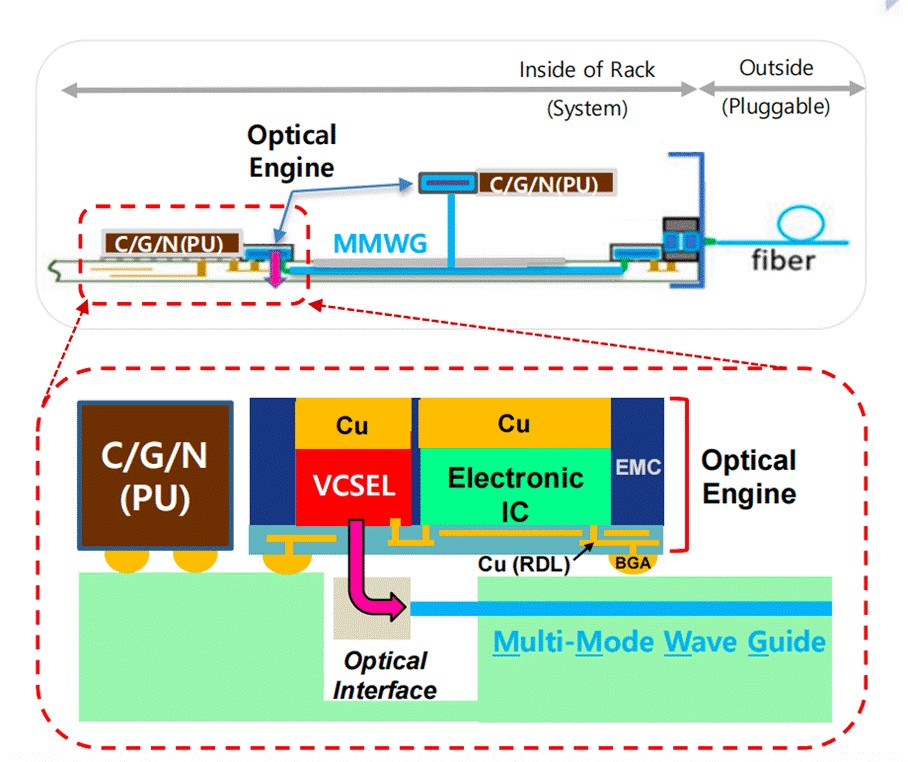
第四代:真正的 CPO
在 CPO(Co-Packaged Optics) 架构中,计算芯片与光引擎在封装层面集成为单一芯粒(Chiplet),外部铜互连被彻底消除。晶圆级封装与装配技术,被视为推动这一代技术落地的关键。
第五代:无 PCB 的光系统
从更长远看,光连接将引入外置或集成激光系统(ELS / ILS),并结合单片光电集成技术,逐步演进为无需 PCB 的光互连系统。
要在系统层面实现高速、低功耗光连接,必须依赖光集成电路(PIC)。其核心在于将激光、调制、复用、探测等功能,在半导体工艺与封装层面实现高密度集成。当前,基于 SOI 的硅光子技术已较为成熟,但在调制器尺寸、功耗与温度稳定性方面仍存在挑战。TFLN、III-V/Si 异质集成、等离激元与非周期纳米光子结构,正被视为突破现有瓶颈的关键方向。从调制器、MUX/DEMUX、波导,到最终的光交换与光路由,光连接技术正逐步从“通信器件”,演进为具备计算与逻辑能力的系统级基础设施。
综合光连接路线图与当前光连接产业的现状,预测到 2040 年的中长期技术开发路线图如下所示,并以单通道(Lane,1 根光纤)可实现的数据传输速率为基准进行整理。在中期阶段,光连接将从 2025 年起逐步导入基于 PAM4 的 200Gbps/lane 方案,并向 400Gbps/lane 演进;与此同时,系统内部光连接将进入第三代NPO(Near-Packaged Optics) 的探索与导入阶段。更关键的是,这一阶段预计将推动形成硅光子相关的产业标准,为后续更激进的封装集成与系统架构演进打下统一接口与规模化基础。
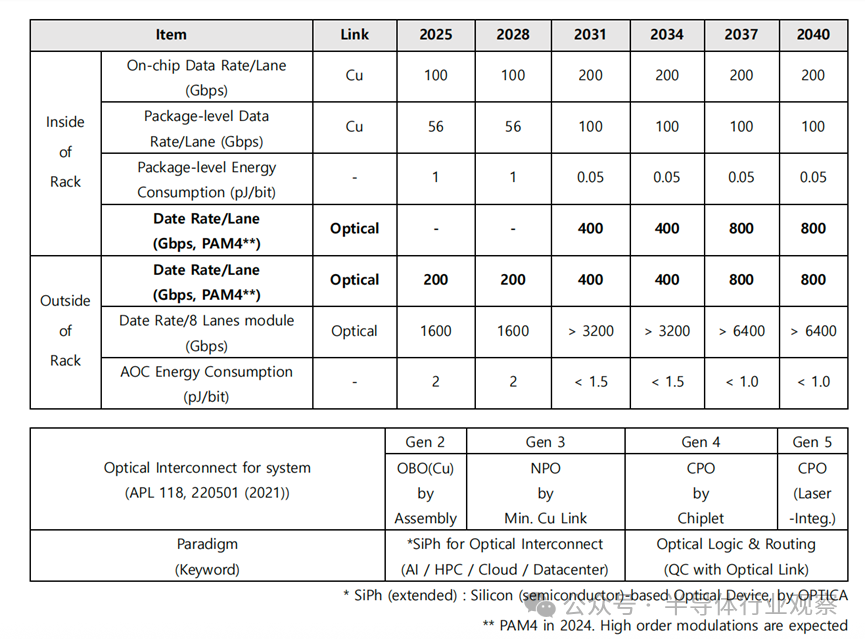
光连接半导体技术路线图
从长期来看,路线图指向 800Gbps/lane 以上的单通道能力,这将推动第四代CPO进入更广泛的实际应用。与此同时,为了支撑超高速传输并进一步降低能耗,系统架构将逐步引入两条关键路径:尽量减少电/光转换次数的混合电/光(Hybrid E/O)体系;面向更极致目标的 光逻辑(Optical Logic) 与光学信息处理能力。更进一步,围绕光逻辑的材料、器件、系统技术体系,以及与量子计算的融合协同,有望在“超高速计算 + 超高速互连”这一组合领域带来非线性级别的突破。
为了支撑上述路线,未来约 5 年的中期阶段,核心工程问题集中在“能跑得更快、跑得更稳、跑得更省”三件事上:
-
速率提升与信号完整性:在更高速率下抑制失真与误码
-
延迟下降:将信号等待时间从“数微秒”压到“数纳秒”量级
-
功耗与热管理:降低驱动功耗与发热,控制系统总功耗
-
小型化与高密度:在更小的 Form Factor 内实现更高带宽密度
与此同时,光连接向其他产业扩展,也将以“光引擎 + 类似原理的光传感器”为技术支点,尤其是 ToF / LiDAR 形态的三维测距能力,进入智能手机、车载系统等规模化平台,并进一步推动航空航天、医疗、工业现场与家庭场景的轻薄短小新系统导入。
对于当前最主要的应用场景——数据中心大数据传输——光连接将在 AI/LLM 训练推理、高性能计算(HPC)与多形态云系统中持续扩大渗透,并在缓解数据瓶颈、降低能耗、减少设施运维成本与推动环保等方面给出系统级解法。
长期(约 15 年)真正难啃的骨头,是数据中心互连的结构性问题:即便大量引入光连接,只要系统仍频繁经历电/光/电的往返转换,延迟与功耗的上限就仍然存在。因此,路线图提出的关键对策之一,是引入光学路由(Optical Routing)。基于 MEMS 的混合电/光路由(Hybrid E/O Routing)已经在实验层面展示了可行性,并有潜力从系统间互连扩展到系统内部:包括计算装置之间、计算与存储之间的数据流动。
要让光学路由真正成为“体系能力”,前提是引入某种形式的光学逻辑(Optical Logic),使系统能够在光域完成:指令解码、可用路径识别、数据流切换与冲突处理。这可能意味着:不仅需要新材料、新器件与新结构,还需要围绕“尽量少做一次电/光/电转换”建立统一的标准接口与适配体系。
更激进也更具想象力的方向,是光学逻辑与量子计算的结合。一旦这条路径成熟,它可能成为真正的“规则改变者”:在提升速率、降低失真、压缩等待时间、降低功耗与实现高密度集成等维度同时带来跃迁。
在更前沿的方向上,路线图还指向用于通信的结构光。例如,将轨道角动量引入数据传输,可实现模式分割复用,并与 WDM(波分复用)、PDM(偏振复用)叠加,从而在理论上打开更大的容量空间。此外,一系列面向“光子信号可控性”的潜在关键技术——包括光学放大、调制(波长/偏振/方向)、乃至激活光子存储器——也可能成为下一代光连接系统的重要拼图。
无线连接半导体路线图
在无线连接领域,下图是ISE预测的无线连接技术路线图:对于 3G/4G/5G 的 Sub-6GHz 主战场,峰值速率目前处于数 Gbps 水平,未来随着基站/终端硬件能力与调制技术提升,预计到 2040 年前后可达到数十至 100Gbps量级。对于 5G/6G 的高频扩展路径,毫米波与亚太赫兹将被更积极地利用。6G 世代的目标指向 0.1~1Tbps(100~1000Gbps)峰值速率,并预计在 2040 年左右,Tbps 级链路将在部分应用场景中实现落地。
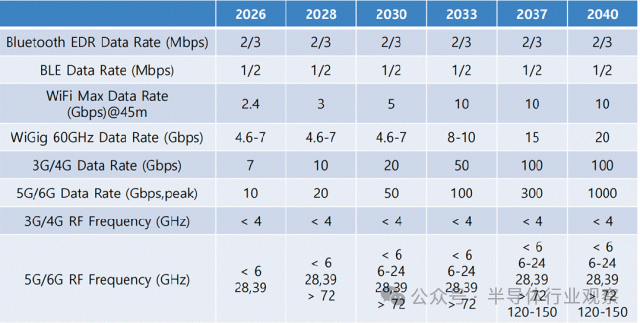
无线连接技术路线图发展趋势
LPWAN、Bluetooth、Wi-Fi 与 5G/6G 等多种标准仍在竞争与分工中共存,为 IoT 设备提供多层次连接能力。由于大量终端需要在极低功耗下长期运行,无线通信器件与电路必须持续提升能效。与此同时,面向 5G/6G 的有源相控阵天线已经取得显著进展:高指向性不仅能以更低功耗实现更远距离通信,还能降低干扰并提升链路安全性。更现实的工程趋势是:将不同材料体系(CMOS/SiGe BiCMOS 与 III-V 等)的器件能力,通过 hybrid 电路设计与先进封装集成为单一系统,正在成为高性能无线平台的关键路径之一。
更重要的是,未来 5G 演进与 6G 愿景的目标,已不再是单纯把峰值速率做高,而是走向“综合质量指标”的系统级提升:时延、能效、可靠性将与吞吐量同等重要。6G 愿景中提出将端到端时延从毫秒级压到 数百微秒以下,并将每比特能耗降至 数十 pJ/bit以下——这意味着无线连接半导体必须在核心模块上持续突破:更高效率且更高线性的 PA、更低相位噪声的频率合成器,以及支撑大规模相控阵与波束成形的 RF-SoC 平台。
在 6G 时代,ISAC(感知与通信一体化)预计将成为无线连接半导体的重要应用方向:同一套 RF 前端与基带平台既要做通信,也要做高分辨率雷达感知。除传统 PA/LNA 与频率合成器外,还需要脉冲生成电路、高速高分辨率 ADC,以及能够对公共硬件资源进行动态重构的 RF-SoC 架构。与此同时,随着低轨卫星(LEO)推动的 NTN(天地一体化网络)扩展,面向卫星终端的 RF 前端与波束成形芯片组需求也将显著增长。在这一领域,GaN HEMT、InP HEMT 等 III-V 器件与 CMOS/SiGe BiCMOS的融合设计与封装能力,可能成为决定系统性能、成本与可规模化程度的关键。
传感器技术
随着人工智能在产业中的深入应用,减少人工干预、提升系统自主性正在成为主流范式。作为自动化系统的核心输入端,传感器在精度、可靠性与信息维度上持续演进。受益于半导体工艺进步与新材料引入,传感器不仅测得更准,也开始获取过去难以检测的新信息。按照信息获取方式,本路线图将传感器划分为成像传感器与检测类传感器,并在此基础上讨论其技术演进方向及与 AI 的融合趋势。
图像传感器技术演进
对于可见光图像传感器而言,像素微缩仍是核心主线。过去二十年中,消费级 CIS 像素尺寸从 5.6 μm 缩小至 0.5 μm,图像质量却持续提升,关键在于多次结构性创新:PPD 降低噪声与暗电流、BSI 将填充因子提升至接近 100%、DTI / FDTI 抑制像素串扰、Tetra Pixel 结合算法提升低照度性能。
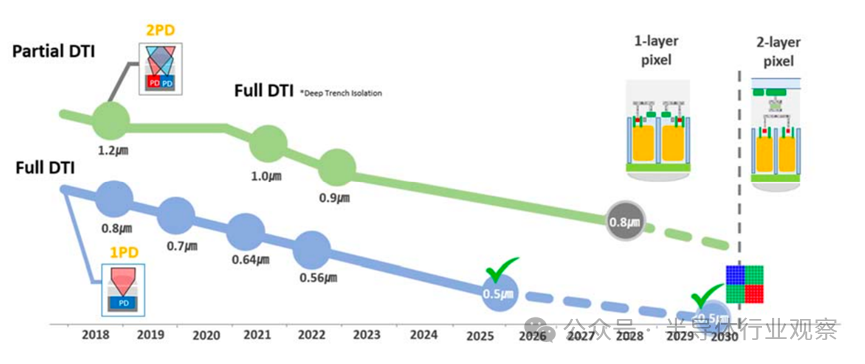
像素微缩趋势与关键技术
随着像素进入亚微米尺度,灵敏度、串扰与光衍射成为瓶颈,未来像素微缩节奏将放缓。为突破灵敏度限制,超构光学(meta optics) 等新型光学结构开始受到关注。HDR 技术方面,多重曝光与单次曝光并行发展。面向视频与车载应用,行业正加速采用多种单次曝光方案,并将 LED Flicker Mitigation(LFM) 作为关键竞争指标。车载 CIS 已实现单次曝光超过 120 dB 的动态范围。在基础性能上,随机噪声(RN) 随工艺与电路优化持续降低,未来有望进入 1 e⁻ 以下;功耗在性能提升背景下仍受控,整体呈下降趋势。在结构上,晶圆堆叠(2-stack → 3-stack) 正成为高性能 CIS 的标配,并为新型传感器结构释放空间。
下一代成像结构的发展趋势如下:
-
全局快门(GS)/混合 GS:通过 3D 堆叠等技术缓解 GS 在噪声与像素尺寸上的劣势,推动其向移动端渗透。
-
数字像素传感器(DPS):像素内集成 ADC,天然支持 GS 与高帧率,借助 3D 堆叠逐步向消费级应用靠近。
-
光子计数传感器(PCS):具备单光子检测能力,在极低照度下优势显著,但在像素尺寸、功耗与成本上仍面临挑战,短期内主要处于研究与探索阶段。
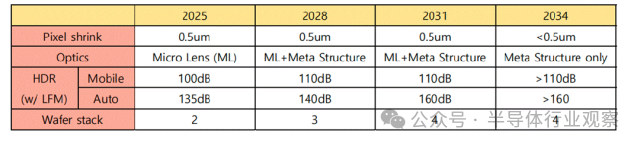
可见光传感器技术路线图
非可见光图像传感器
非可见光传感器覆盖 UV、NIR、SWIR、LWIR 波段,应用从军用扩展至工业、医疗、自动驾驶等领域。
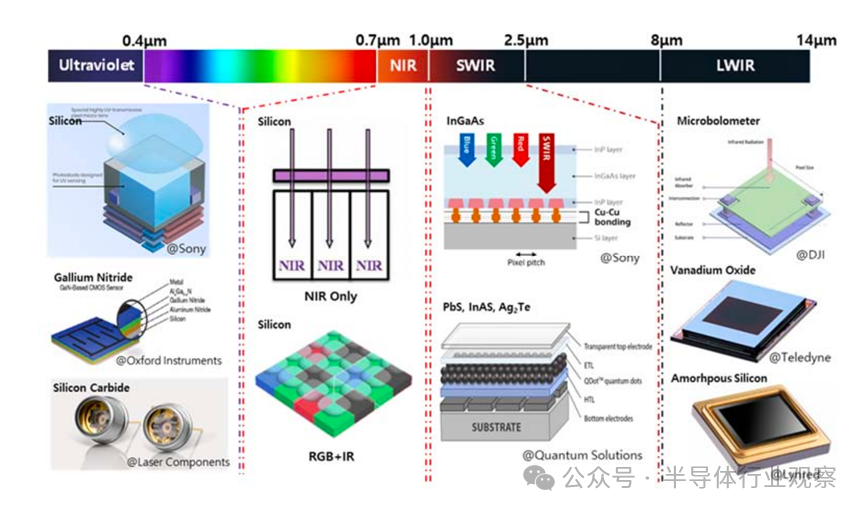
非可见光波段图像传感器的吸收材料
UV(200–400 nm):以硅基为主,但受限于表面吸收过强与 QE 偏低,正探索 PQD、SiC、GaN 等宽禁带材料。
NIR(700–1000 nm):仍沿硅基路线演进,SPAD 技术推动 LiDAR 与低照度应用发展;RGB+IR 结构成为新趋势。
SWIR(1.0–2.5 μm):当前以 InGaAs 为主,性能优但成本高;QD(PbS、InAs、Ag₂Te) 与 Ge 被视为潜在替代方案,关键在于 QE、RoHS 合规与量产能力。
LWIR(8–14 μm):以微测辐射热计(VOx / a-Si)为主,受限于工艺复杂与像素微缩难度,材料与结构简化仍是研究重点。
事件驱动与检测类传感器
事件驱动视觉传感器(EVS) 以异步方式仅输出光强变化事件,具备高时间分辨率与低功耗优势,适合高速目标检测。未来发展重点包括:像素微缩、低照度与 HDR 改善,以及 事件信号处理 IP 与 On-sensor AI 的引入。
面向 AI 时代的传感器趋势
三条方向尤为明确:
In-Sensor DNN:在 CIS 内部集成 DNN,仅输出特征或元数据,可获得 百倍级能效优势,缓解接口与带宽瓶颈。
超低功耗(AON):通过情境感知、ROI 读取与轻量模型,实现“常开但不耗电”的感知体系。
多传感器融合:融合视觉、雷达、LiDAR、IMU 等信息,提升系统鲁棒性,并向协同感知(V2X / CP)演进。
总的来说,传感器正从“记录世界”走向“理解世界”。在单一性能指标逐步逼近极限的背景下,AI 驱动的计算前移、结构创新与多传感器融合将成为决定未来传感器价值的关键因素。传感器不再只是数据源,而是 智能系统中的主动计算节点。
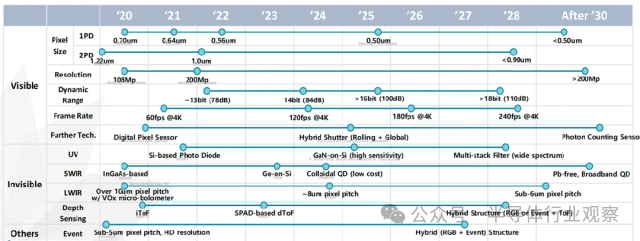
传感器技术发展动向路线图
有线互连半导体技术
有线互连可定义为:在半导体系统中利用金属布线实现芯片间通信的技术。按集成层级可归纳为三条主线:
封装层级:异构集成
异构集成在封装层实现系统级集成,典型形式包括中介层(interposer)与芯粒(chiplet)架构。中介层的核心价值在于用具备更高布线密度的结构/材料,替代传统封装基板,以缩短互连距离并提升 I/O 密度,从而改善信号传输能力。
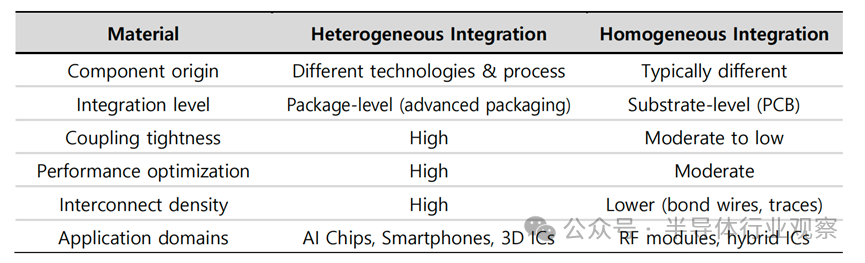
上图对比了异构集成与单片集成的差异,如上所述,异构集成中最具代表性的核心推动要素是中介层
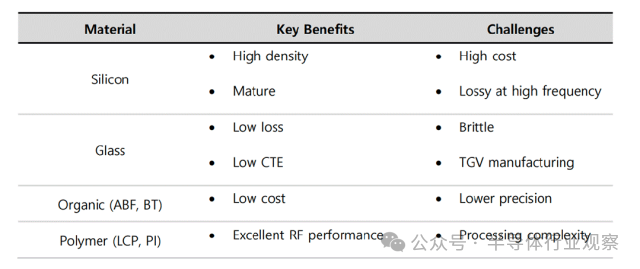
上图进一步比较不同材料中介层的优势与局限。由于材料特性差异明确,中介层选择应由系统目标(损耗、成本、集成度、可靠性等)驱动
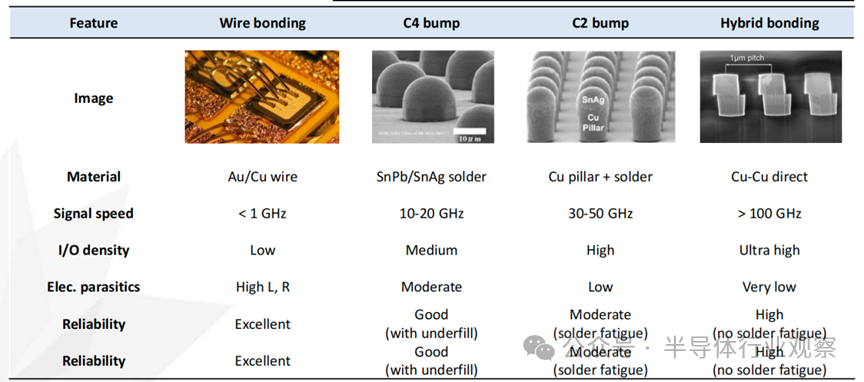
封装中主要互连方式比较
用于高速系统封装中有线互连的互连技术主要可分为四类,按开发顺序依次为:(1)引线键合(wire bonding,WB),(2)受控塌陷芯片连接(controlled collapse chip connection,C4)凸点,(3)芯片连接(chip connection,C2)凸点,以及(4)混合键合(hybrid bonding)。如上表中所示,引线键合虽然具有较高的可靠性,但由于其电气寄生参数较大,可传输的信号带宽通常低于 1 GHz。C4 凸点采用锡-铅合金,相较于 WB 具有更短的互连长度和更小的寄生参数,其可支持的信号带宽一般在 10–20 GHz 范围内。为进一步提升 C4 凸点的集成密度,引入了铜柱(Cu pillar),并在此基础上提出了 C2 凸点技术,以实现更高的互连密度。最后,通过同时实现介电材料与铜的键合,提出了混合键合技术,从而达成目前最高集成度的互连方案。
在中介层中,关键的连接要素是硅通孔(Through Silicon Via,TSV),其长度相比传统互连方式如引线键合(WB)要短得多。互连长度的缩短可显著降低寄生电感与电阻,从而改善信号传输特性。借助 TSV,不仅可以提升半导体系统的集成度,还能够同步提高系统性能。在硅中介层中使用的 TSV,在玻璃基板中对应的是玻璃通孔(Through Glass Via,TGV)。与 TSV 类似,TGV 也是一种垂直互连结构。下表对 TSV 与 TGV 进行了比较,其主要差异来源于材料特性的不同。这种差异主要是由于硅与玻璃的介电常数不同所致,介电常数反映了材料对高频信号的响应特性。正因如此,硅和玻璃在实际应用中的使用领域各有侧重;此外,玻璃基板还可实现面板级工艺,在成本方面也具备一定优势。

TSV与TGV的比较
芯片层级:芯粒(Chiplet)
芯粒将原本单片制造的整体芯片拆分为多个子芯片单元,分别采用更合适的工艺制造,并在封装阶段集成。可以理解为:中介层偏“封装层提升集成”,芯粒偏“硅层拆分重组提升集成”。
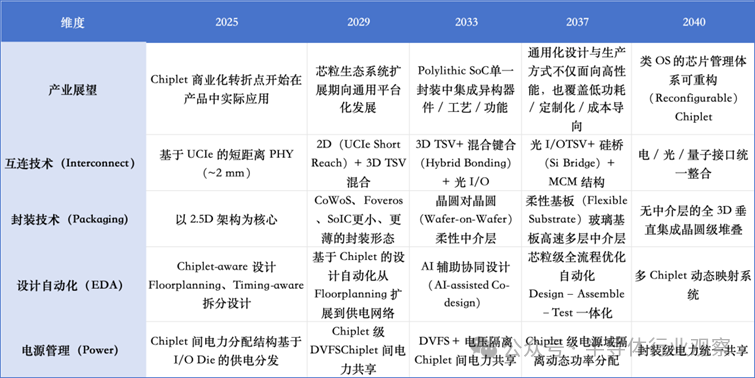
Chiplet技术路线图
产业趋势:芯粒将经历商业化落地与生态扩展阶段,系统架构向集成多类异构芯片的 Polylithic SoC 演进,并围绕标准接口形成通用设计与制造体系;长期看,资源与功能的统一管理有望上升到 OS/系统层的“芯片管理”范式。
芯粒互连标准:主要包括 BoW、AIB、UCIe。其中 UCIe 采用差分串行链路,支持均衡与编码,并引入 CDR(时钟数据恢复),减少对独立时钟分发的依赖。综合信号完整性、抗噪与可扩展性,UCIe 在有限带宽条件下优势更突出,且可支持更长互连距离(最高可达 10 mm),因此更适合高性能芯粒架构。
封装技术:早期以 2.5D(如 CoWoS、Foveros、SoIC 等)提升互连密度并保证 SI;随后 Wafer-on-Wafer 与柔性基板提升堆叠自由度;长期目标是减少中介层依赖、走向更彻底的 3D 垂直集成。
设计自动化:从 chiplet-aware 设计到 AI 辅助协同优化,最终走向可对多芯粒进行动态映射与全系统级优化的高度自动化体系。
电源管理:从芯粒间供电路径优化,到芯粒级 DVFS,再到封装层面电力共享与协调的统一管理。
电路层级:SerDes 演进
SerDes 是高速互连的关键:将大量数字信号映射为高速链路可承载的信号形式,实现可靠传输。下图展示了 2000–2024 年不同 SerDes 标准规定的数据速率演进趋势:速率提升不仅持续推进,而且呈现近似指数增长。这意味着有线互连所需的频率带宽同样以指数方式增加。
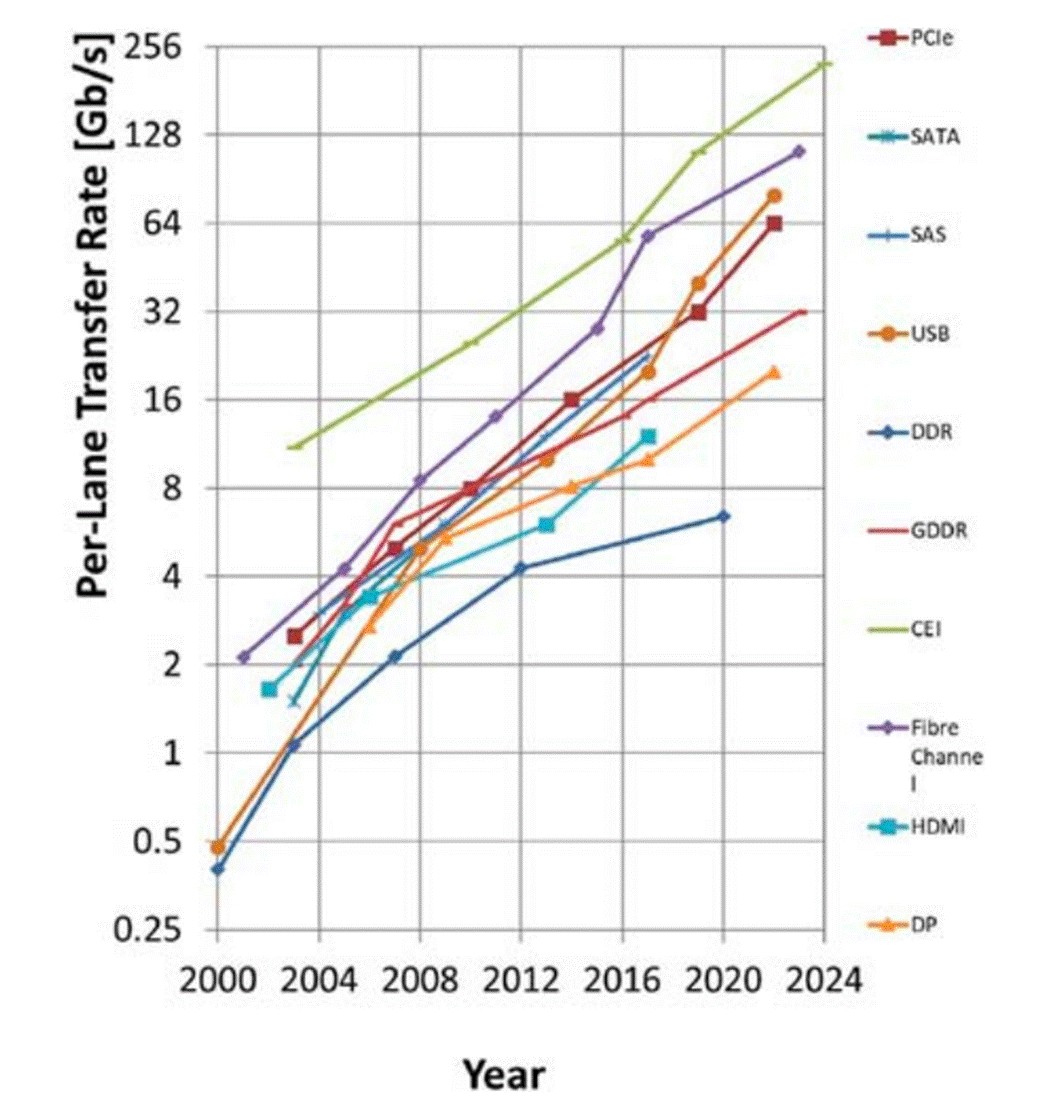
SerDes 规格中数据传输速率的发展趋势
下表对代表性标准(PCIe、以太网、USB 等)进行对比:速率整体仍延续指数提升。为在带宽受限的条件下提高有效传输能力,业界正持续采用更高频谱效率的 PAM 多电平传输;时钟逐步走向嵌入式/恢复式方案以减少布线并缓解相位不匹配;均衡成为标配,其中 CTLE 几乎普遍采用,DFE/FFE 按通道需求选择性引入。
PIM(存内计算,Processing-In-Memory)技术
PIM技术可视为对传统冯·诺依曼架构在AI时代的一次体系级回应。PIM 的核心思想是在存储层附近或内部执行计算,以最小化“算—存”之间的数据传输。根据计算单元与存储单元的物理位置关系,PIM 技术可分为三类:PIM 技术可以具体分为 CIM、PIM 和 PNM 三类。按照这一分类,CIM 更偏向于计算能力,而 PIM 更偏向于存储能力。借助 TSV 等新一代芯片互连技术,PNM 架构有望同时最大化 CIM 与 PIM 各自的优势。ISE的路线图正是将这种 PNM 技术作为未来形态的 PIM 计算架构加以提出。
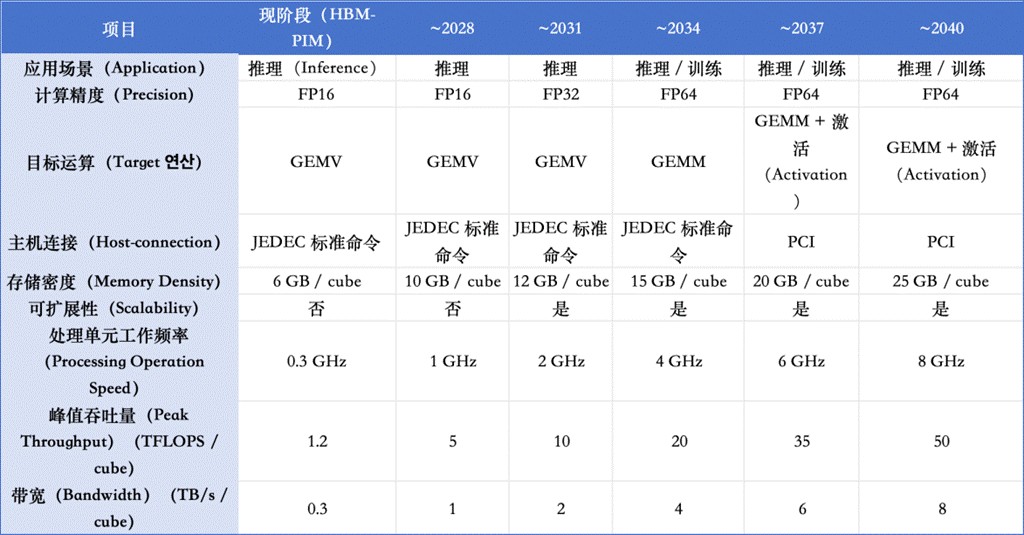
PIM技术路线图
以 PNM 为核心形态的 PIM 架构,具备从加速器向独立计算平台演进的潜力,并有望在未来的数据中心化(data-centric)计算体系中,成为支撑 AI 推理与训练的重要基础硬件形态。PIM 的发展路径可概括为两个阶段:到2034 年:PIM 主要作为 GPU 生态中的高性能组件存在,重点加速推理类 GEMV 运算,并逐步扩展至受限训练场景;到2040 年:PIM 通过 PNM 架构实现规模化互连与协同计算,逐步承担核心计算角色,覆盖推理与训练任务,形成以 PIM 为中心的计算体系。
在结构上,该路线图倾向于采用 DRAM + Base die(逻辑工艺) 的 PNM 形态,通过 TSV 与先进封装实现高带宽互连,并在 Base die 中引入可扩展计算与片内 CIM,以提升系统整体的 roofline 上限。
PIM 技术的进一步发展仍面临若干关键挑战:CIM–PIM 间的 TSV 高带宽、低功耗互连;Base die 与 DRAM die 的功能划分与散热管理;与 Host-processor 软件栈的协同与可编程性问题;PIM Cube 之间的低功耗、超高速互连机制。这些问题不仅涉及器件与封装层面,也直接关系到系统架构与软件生态的接受程度。
半导体封装技术
本路线图将封装技术划分并定义为五个主要方向。第一,介绍将单一芯片封装为一个整体的 Single-Chip 结构,以及将多个芯片集成为一个模块的 Multi-Chip 结构。第二,从封装内部布线与互连的角度,区分传统的 2D 封装、采用高密度中介层或桥接结构的 2.xD 封装,以及垂直堆叠的 3D 封装,并分别进行说明。第三,讨论在晶圆或面板层级同时完成多芯片封装的扇出型晶圆级 / 面板级封装(FO-WLP/PLP)技术。第四,针对 HPC 与数据中心封装,重点介绍构建高性能计算系统所需的核心封装技术,包括基于 Chiplet 的异构集成、超高带宽存储器(HBM)耦合、细间距互连与 Die-to-Die 标准,以及应对高热密度的封装与散热结构。第五,涵盖在高功率、高密度环境中不可或缺的热管理结构,以及支撑整体封装设计的建模、仿真与协同设计(Co-Design)技术。
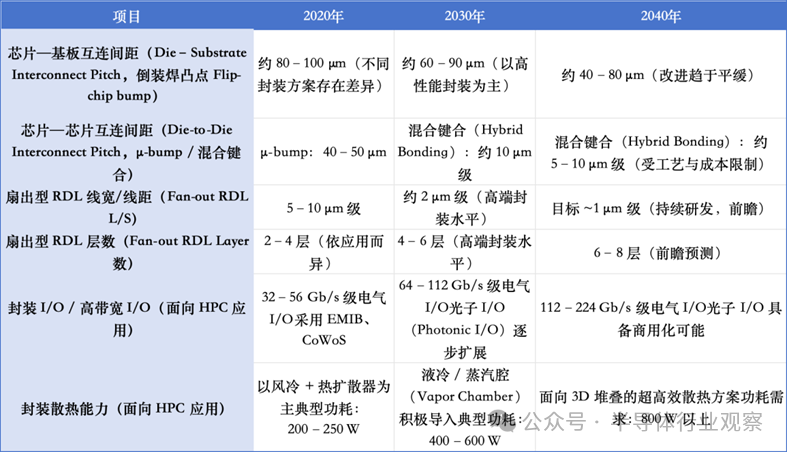
先进封装技术路线图
基于 Single-Chip 的集成方式,正因制程成本上升与大尺寸 die 良率受限而逐步显现出结构性约束。在此背景下,基于 chiplet 的 Multi-Chip Integration 作为新的系统集成方式不断扩散。同时,封装架构正从传统的 2D 结构向 2.xD 与 3D 结构演进,中介层、Fan-out RDL 以及基于混合键合的互连微缩,已成为实现高带宽与低时延特性的关键技术要素。此外,Fan-out 与 PLP 工艺作为同时追求封装微缩与生产效率提升的技术,其应用范围也在逐步扩大。
HPC与数据中心领域是最早、也是最强烈推动上述封装技术变革的代表性应用场景。在这些系统中,基于 chiplet 的架构、HBM 的集成、高密度互连,以及电力与冷却的一体化设计,已成为决定系统性能与可扩展性的核心因素。同时,随着结构向高集成度与高功率密度发展,热管理、多物理场建模以及基于 Co-Design 的综合设计环境,正被视为决定封装性能与可靠性的必备基础技术。
量子计算半导体技术
量子计算通过对量子比特的量子力学现象进行控制,以概率性、可逆的运算方式,相较经典计算机可实现更优异的性能和计算速度。在多种量子比特类型中,超导量子比特因其与半导体工艺的高度兼容性、良好的集成性以及快速的门操作速度,在产业界和学术界得到了极为活跃的研究。
国际上 IBM、Google、Intel、Rigetti、D-Wave 等重点布局超导量子比特;IonQ、Quantinuum 深耕离子阱路线;Xanadu、PsiQuantum 则专注光子量子计算。Google 已通过随机量子电路实验验证量子优越性,Intel 与 QuTech 在低温自旋量子比特方面取得阶段性成果。如下图所示。
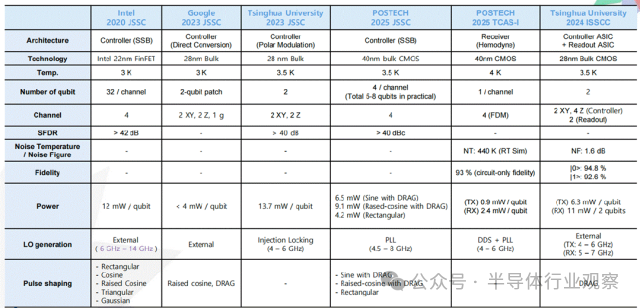
由于在工艺成熟度、集成潜力与半导体兼容性方面具备显著优势,超导量子比特被普遍认为是最具现实可行性的量子计算实现路径之一。近年来,其核心指标——量子比特规模、门操作保真度及纠错能力——持续提升(见下图)。从时间轴看,Google 于 2019 年推出 53 比特 Sycamore;IBM 在 2021–2023 年间相继发布 Eagle(127 比特)、Osprey(433 比特)与 Condor(1,121 比特);2024–2025 年,Heron、Willow 及 Majorana 系列处理器在可靠性、纠错率和新型拓扑架构方面取得突破,标志着系统工程能力的显著提升。
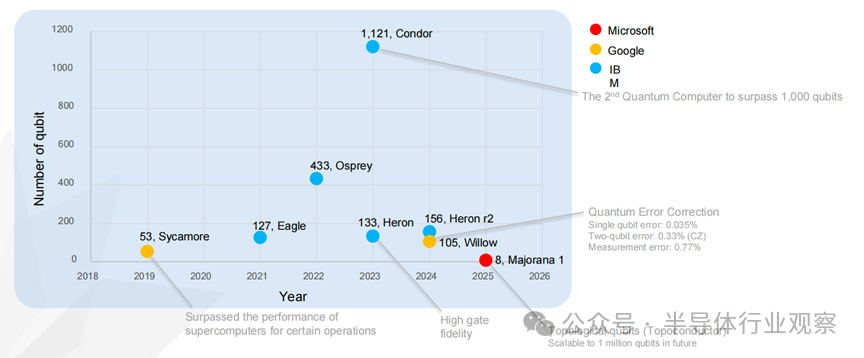
全球量子计算市场正快速增长,量子计算被视为核心驱动力之一。主要企业已不再局限于硬件研发,而是同步构建云端可访问的量子计算服务与软件生态,如 IBM Quantum、Azure Quantum 等。总体趋势显示,硬件—软件—云平台的一体化正在成为量子计算产业化的主线。
综合现有研究与产业规划,量子计算技术正沿着“验证 → 集成 → 容错 → 规模化”的路径演进(见下图)。

2024–2025 年:中等规模量子处理器实现稳定运行,Cryo-CMOS 控制与低温读出逐步集成。
2026–2028 年:数千量子比特级模块化架构出现,自动化纠错机制确立。
2029–2035 年:容错量子计算机与逻辑量子比特规模化落地,量子优势在材料、化学等领域得到验证。
2036–2040 年:量子计算与 HPC、AI 深度融合,形成以 QPU 为核心的量子中心计算平台。
结语
纵观这份长达百余页、跨越15年的路线图,我们看到的不仅是一系列令人惊叹的技术参数,更是半导体产业在面对物理极限时的一次集体“突围”。ISE所描绘的未来,是一个“边界消失”的世界:逻辑与存储通过3D混合键合融为一体,光信号在芯片内部取代铜线穿梭,传感器从单纯的数据采集器进化为拥有自主意识的探测节点,而量子比特则在极低温的寂静中重塑计算的本质。这反映了半导体产业最深层、也最具观察力的转折——单一技术的红利已经枯竭,全栈式的系统集成正成为新的主权边界。在这场通往2040年的长跑中,0.2nm或许是工艺的终局,但对于真正决定计算未来的系统性重构而言,大幕才刚刚开启。
来源:本文内容由作者编译自韩国半导体工程师学会(ISE)「2026半导体技术路线图」,图片均来自路线图白皮书,部分图表由韩文翻译成中文,以便于读者理解。
文章来源: 半导体行业观察
- 还没有人评论,欢迎说说您的想法!



